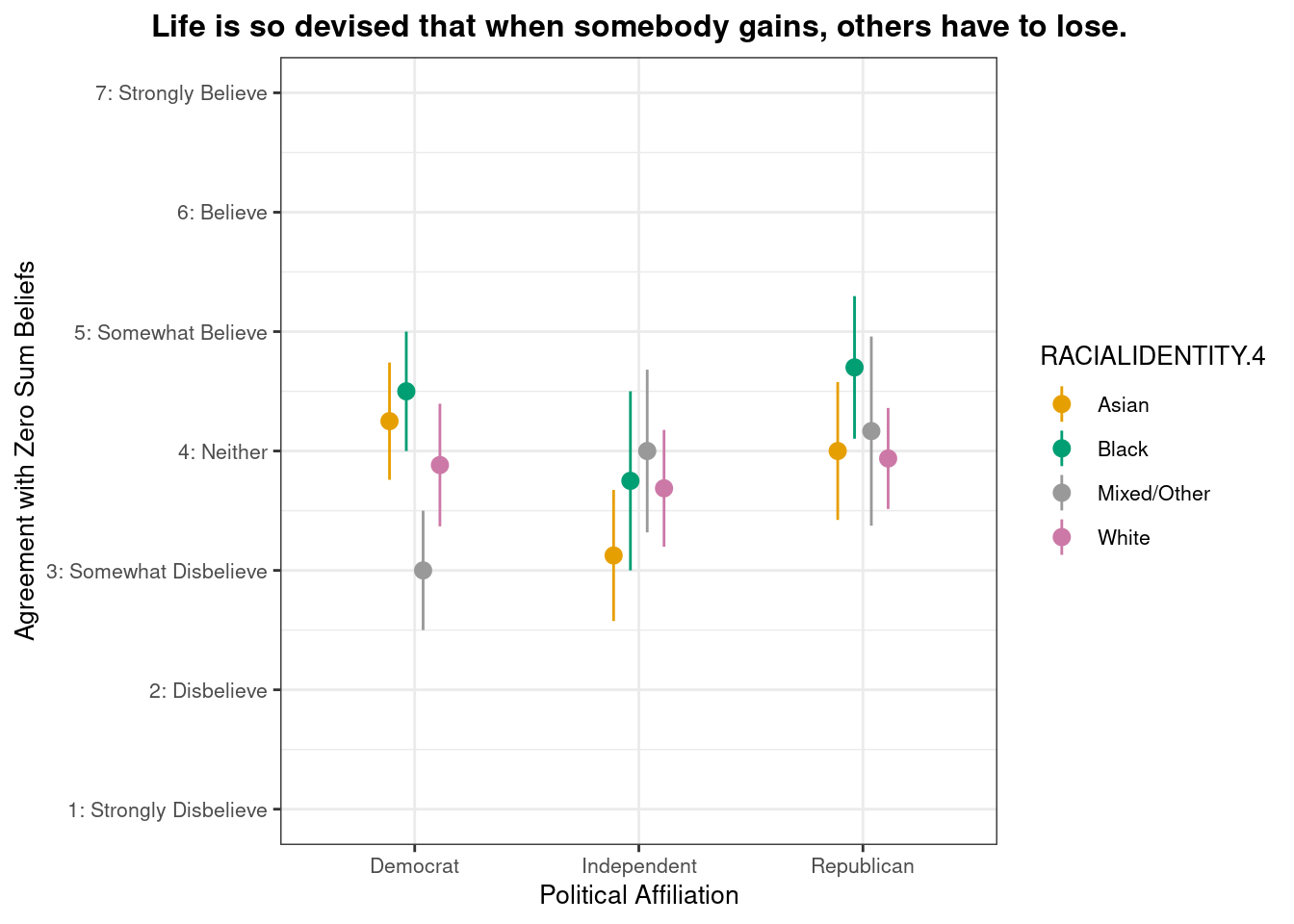
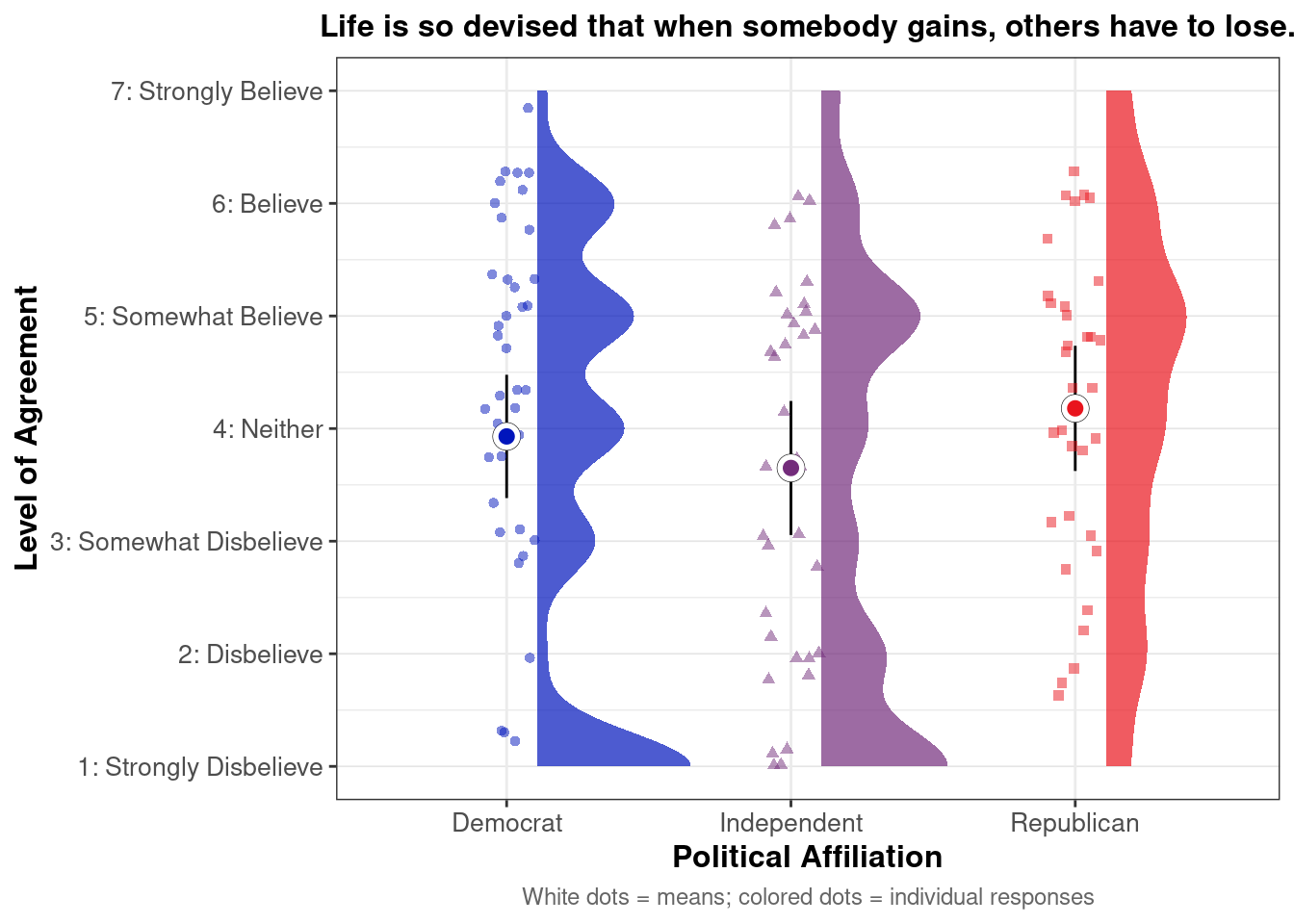
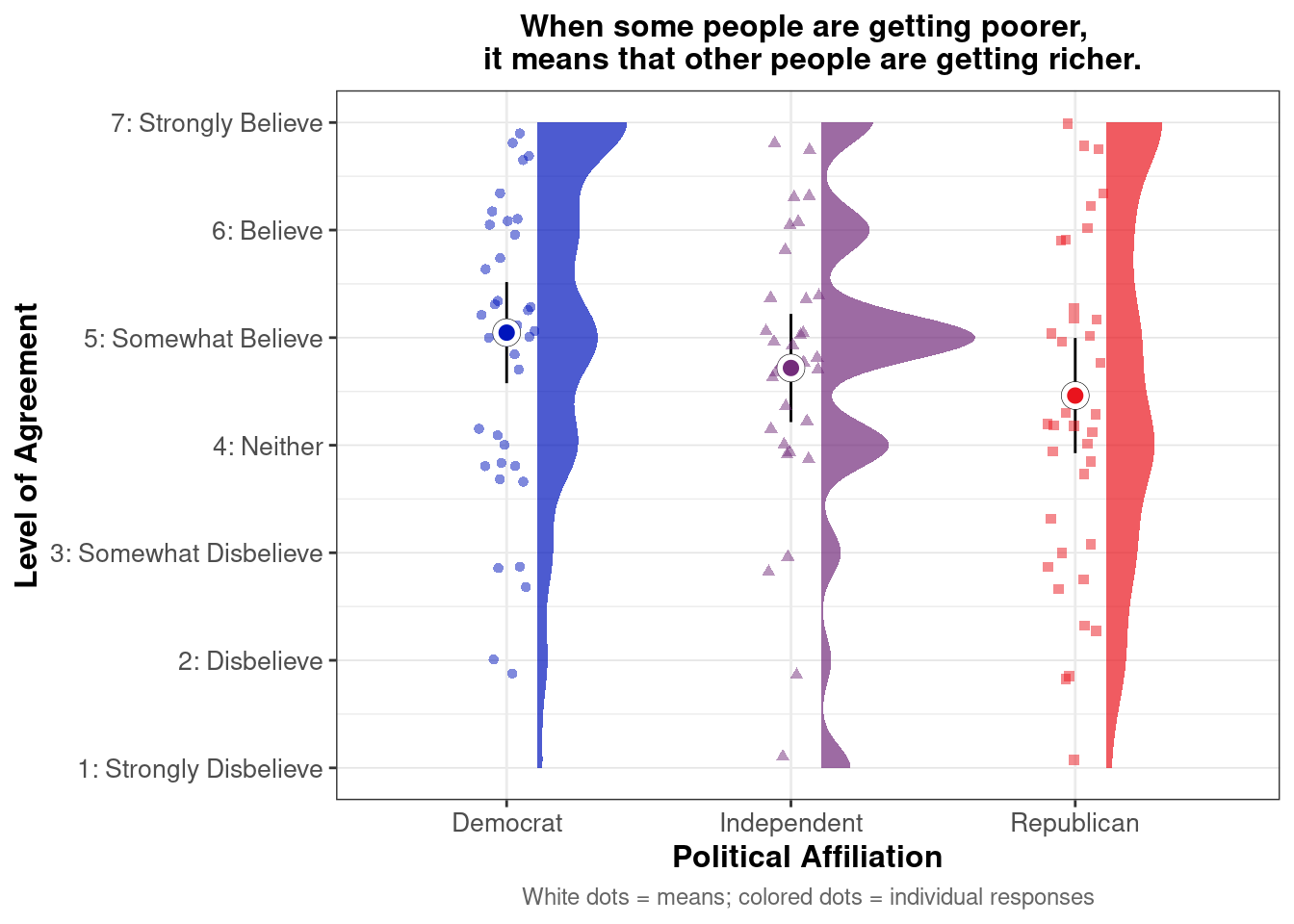
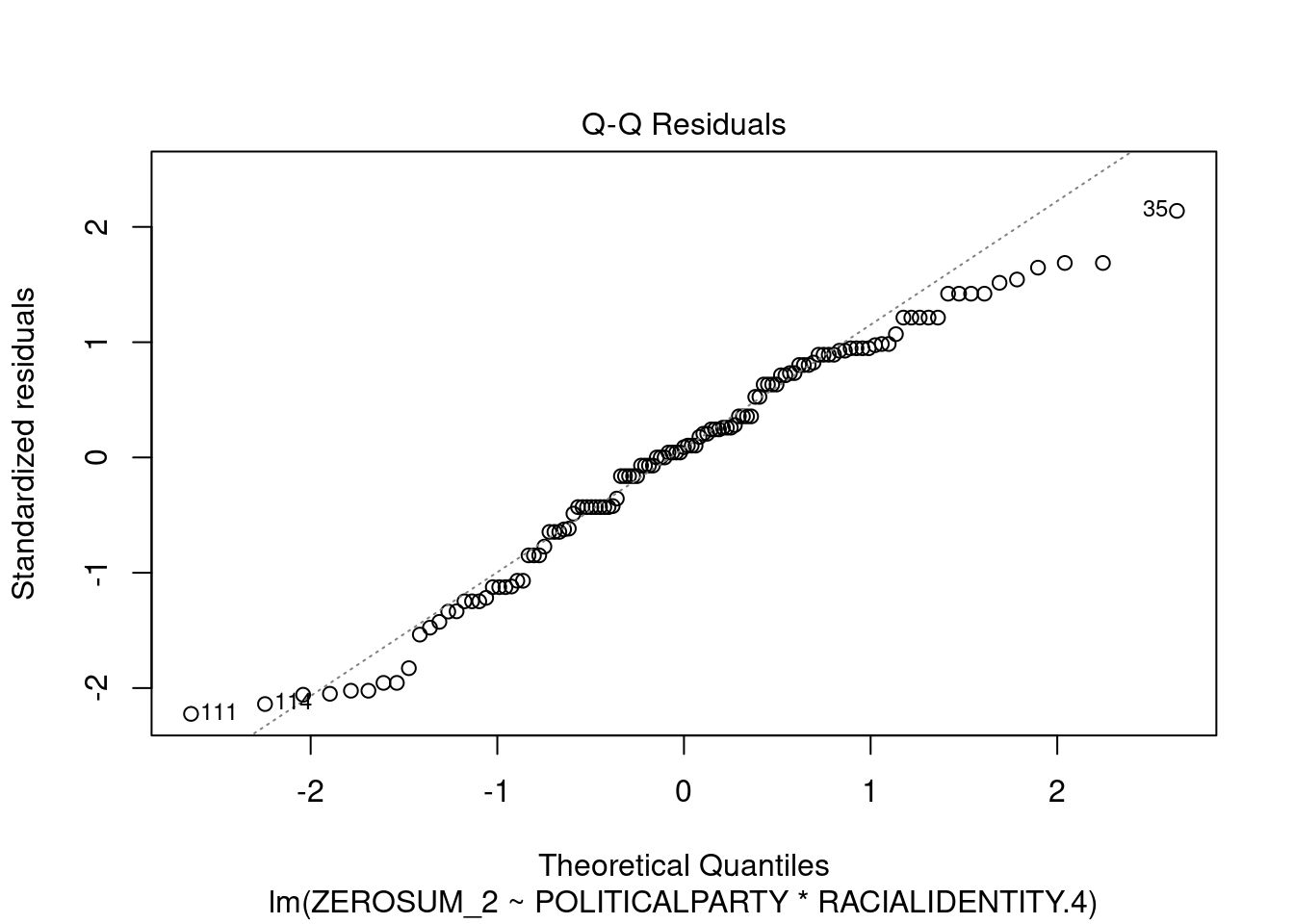
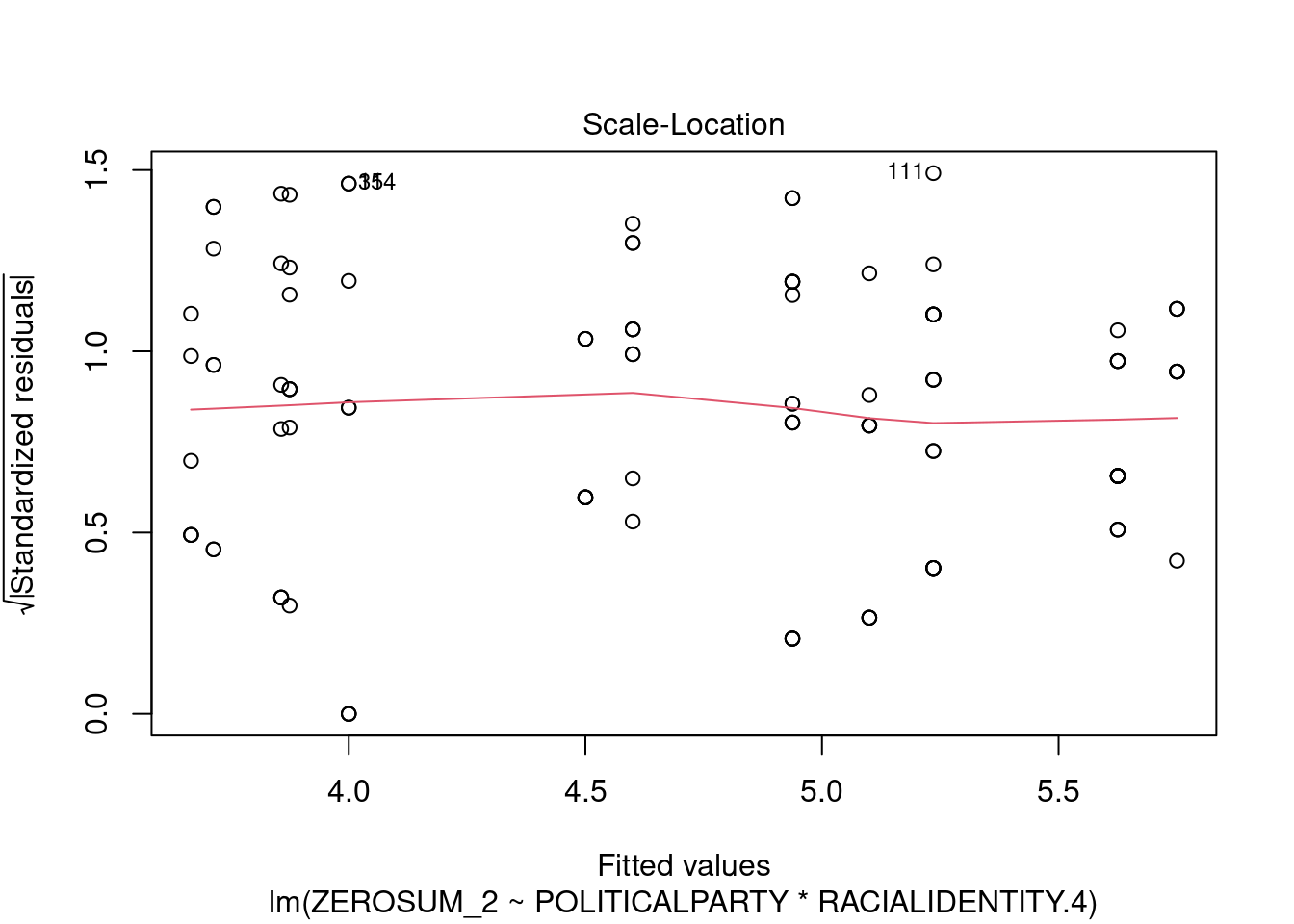
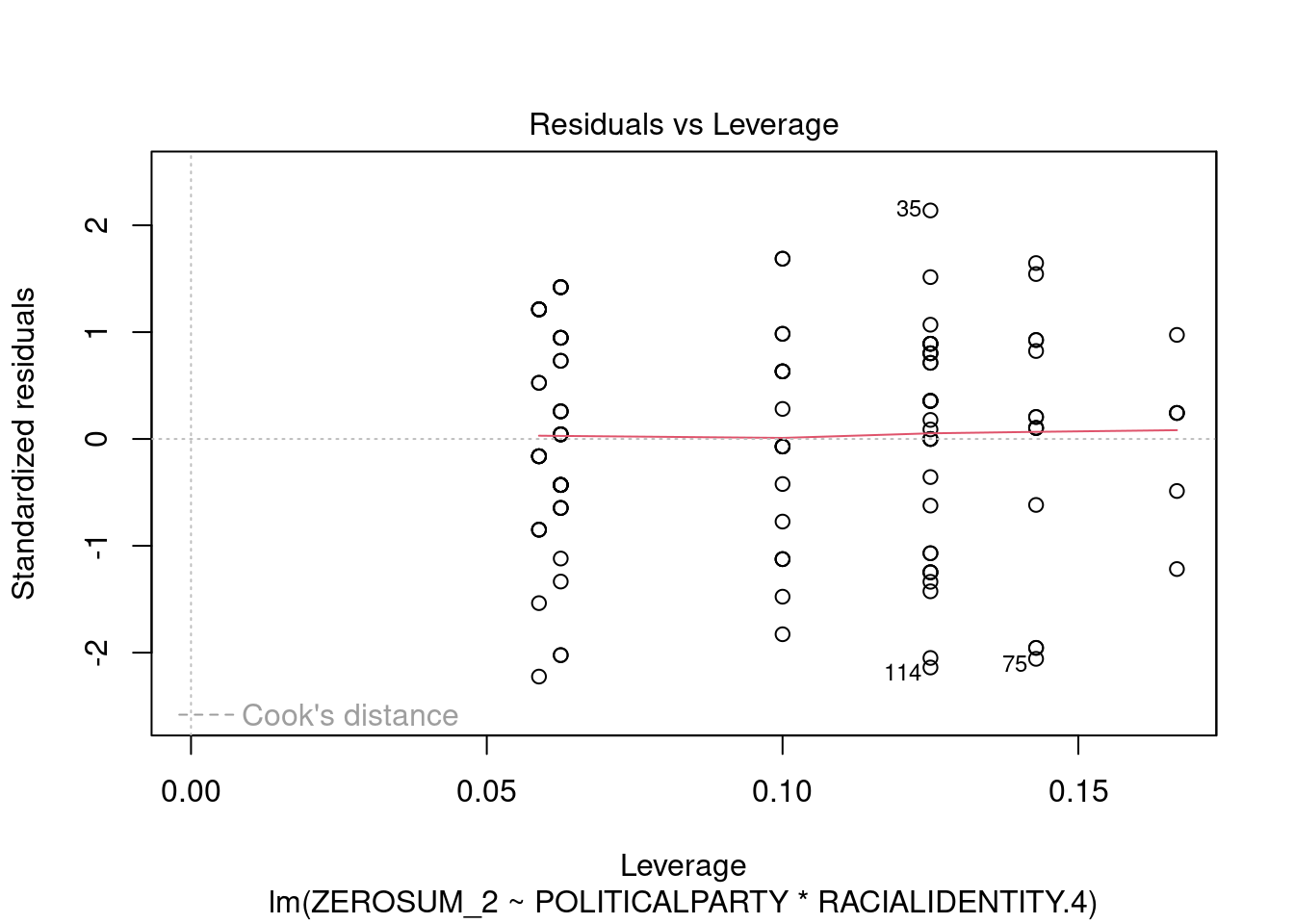
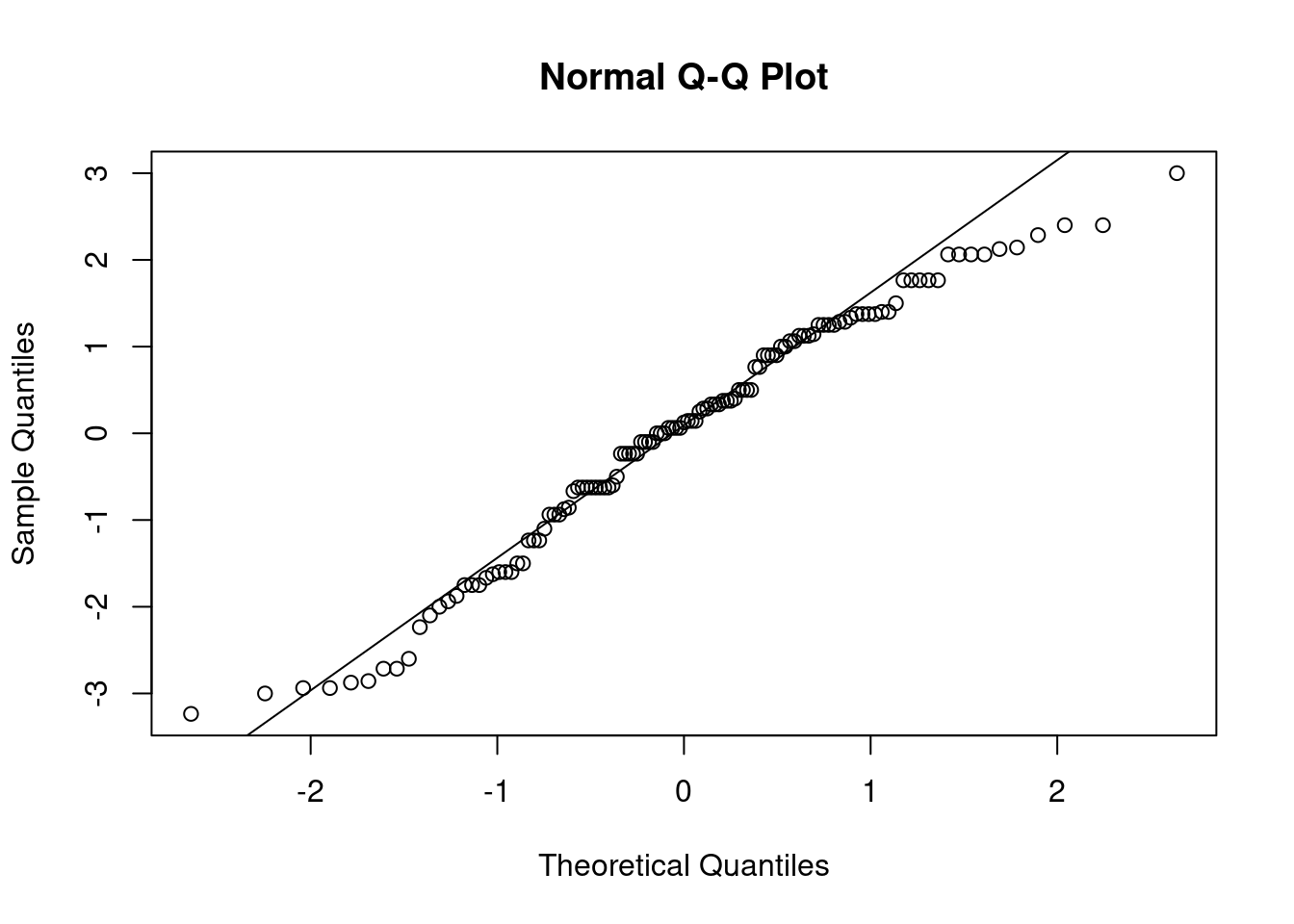
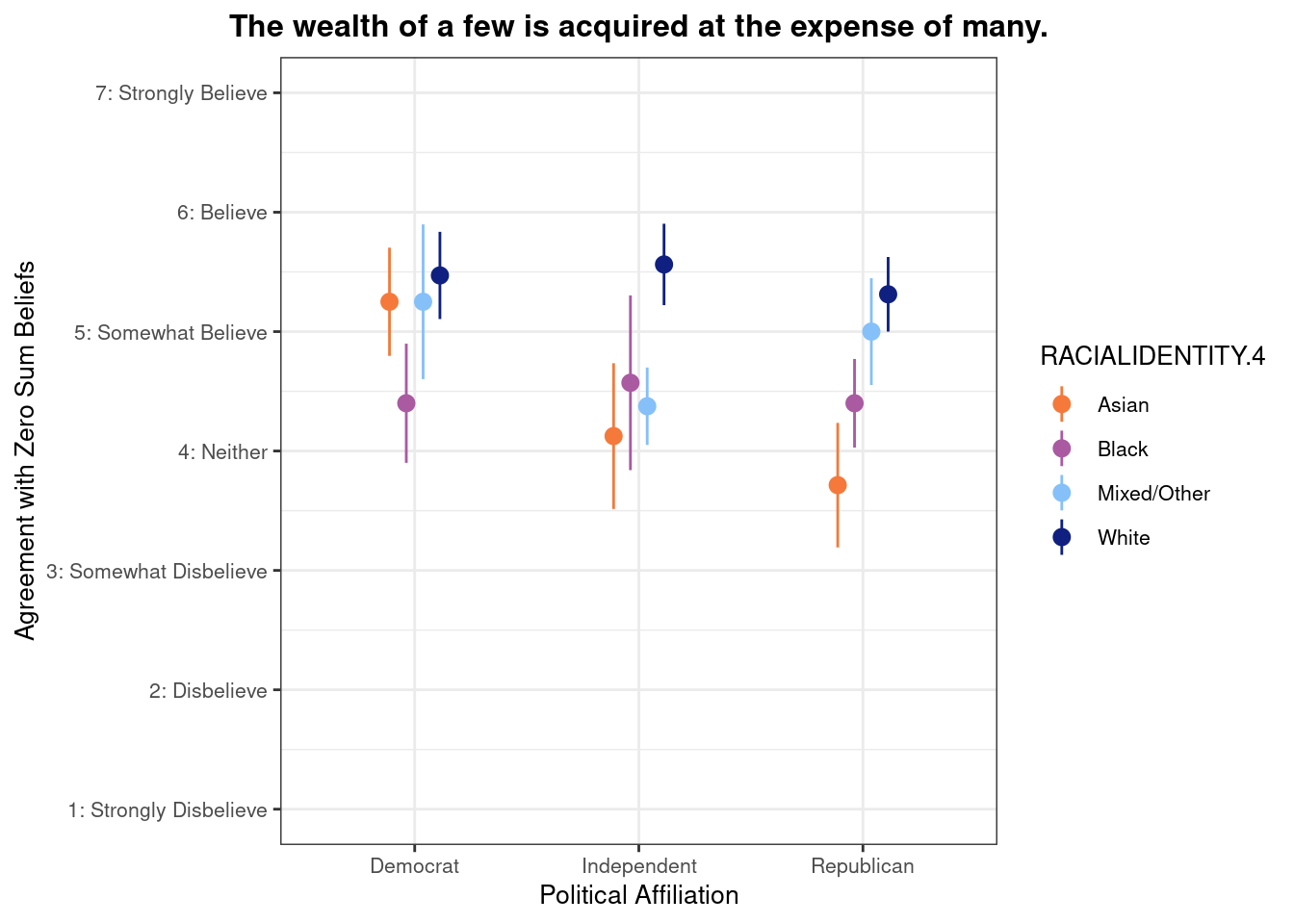
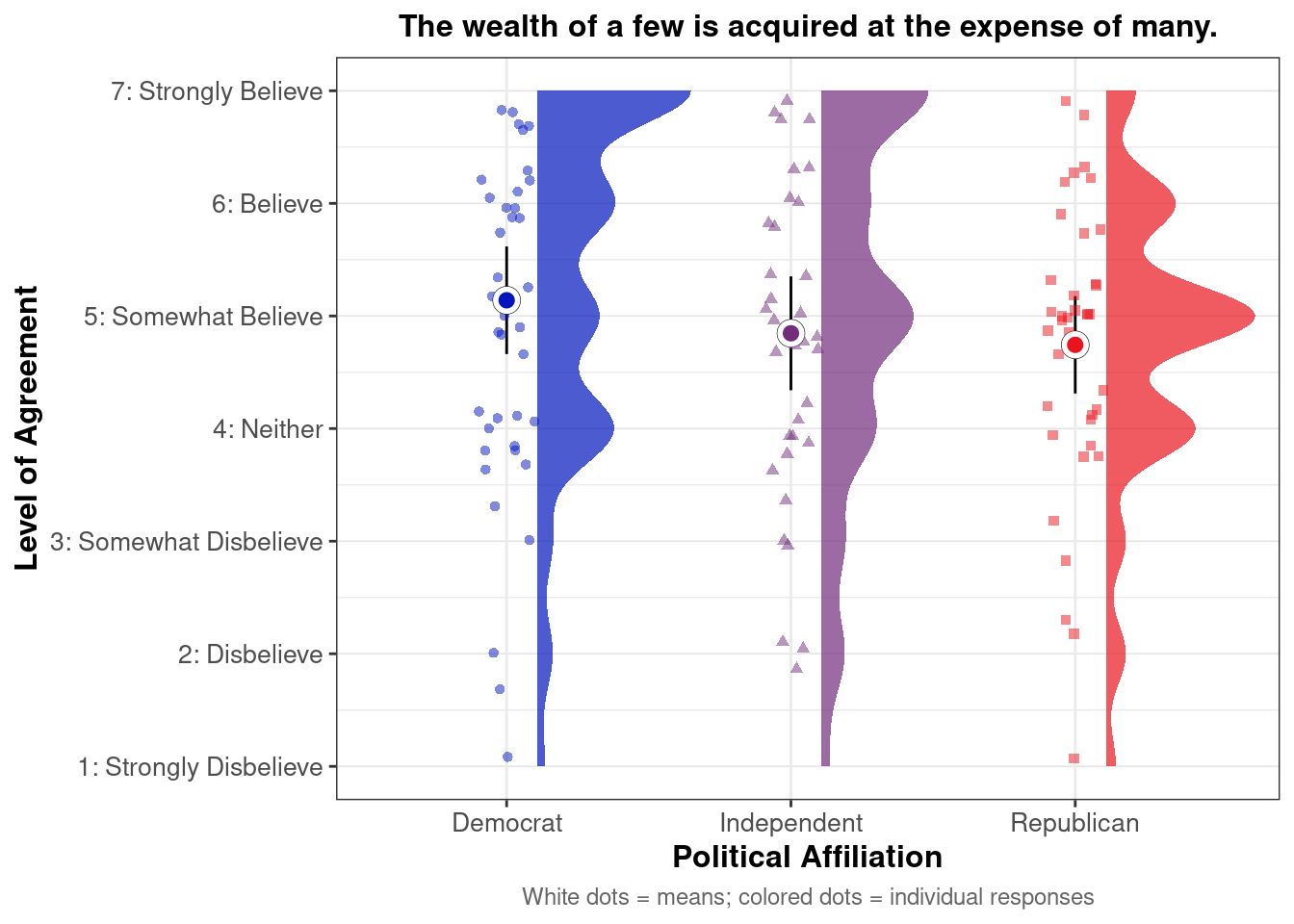
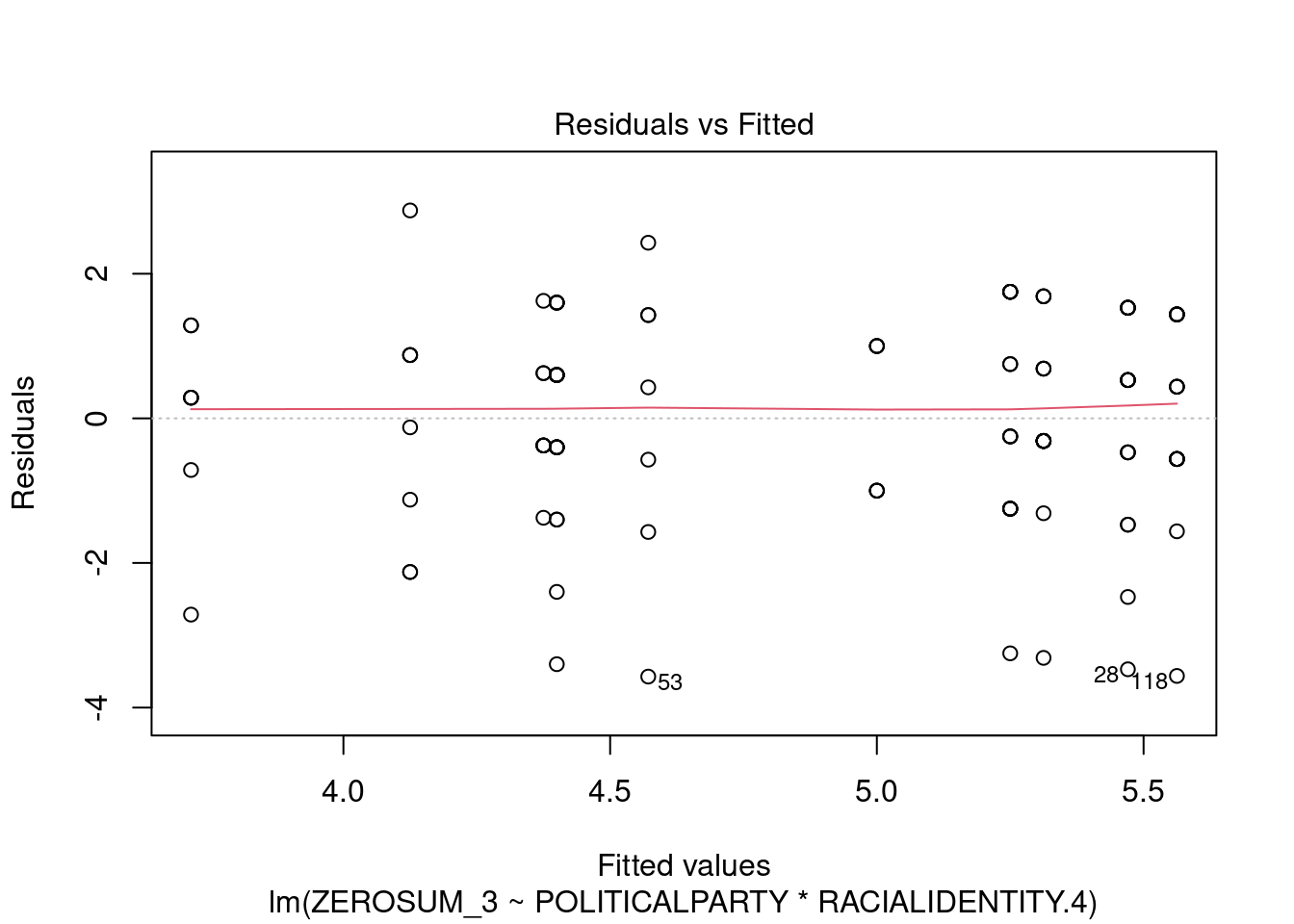
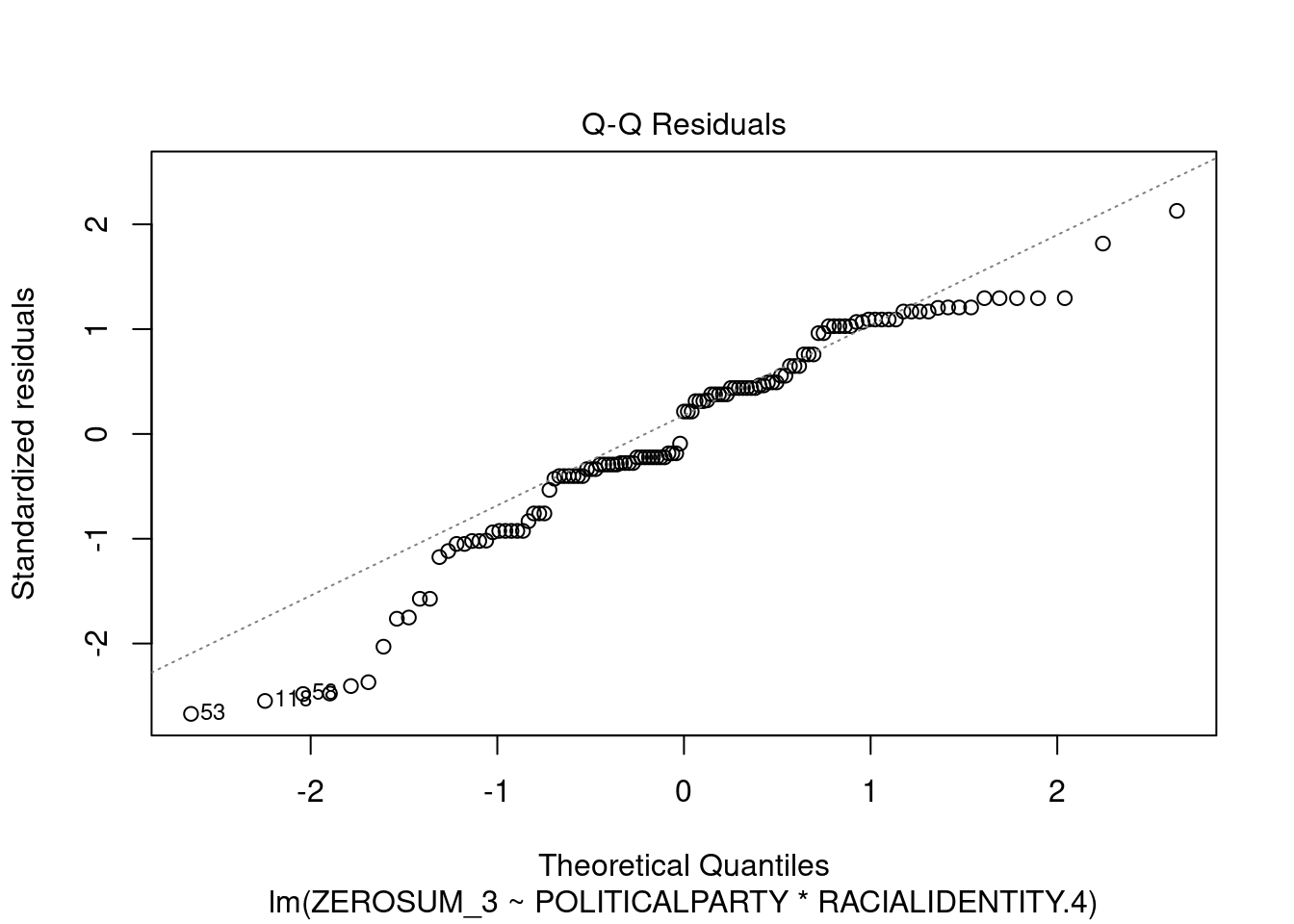
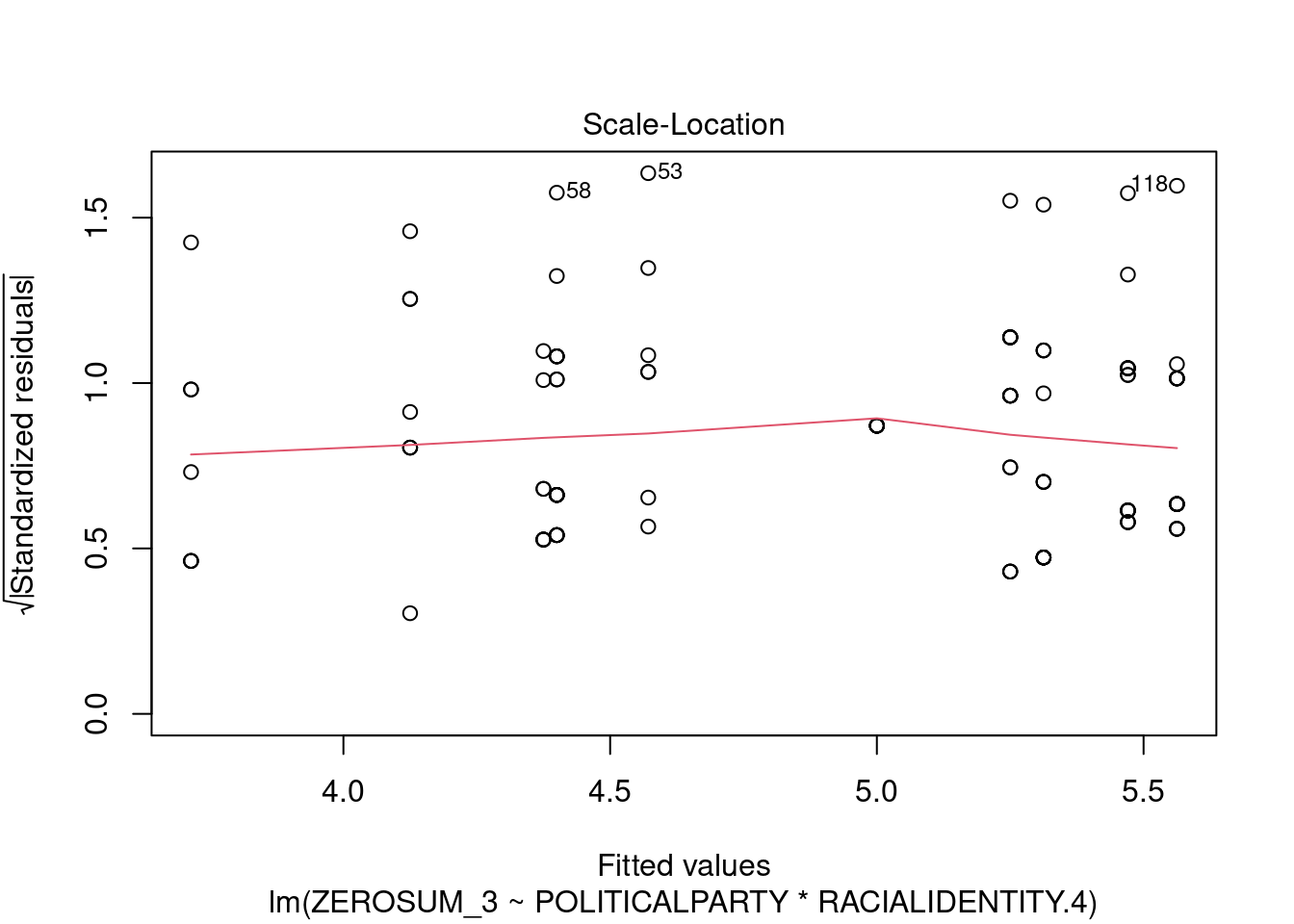
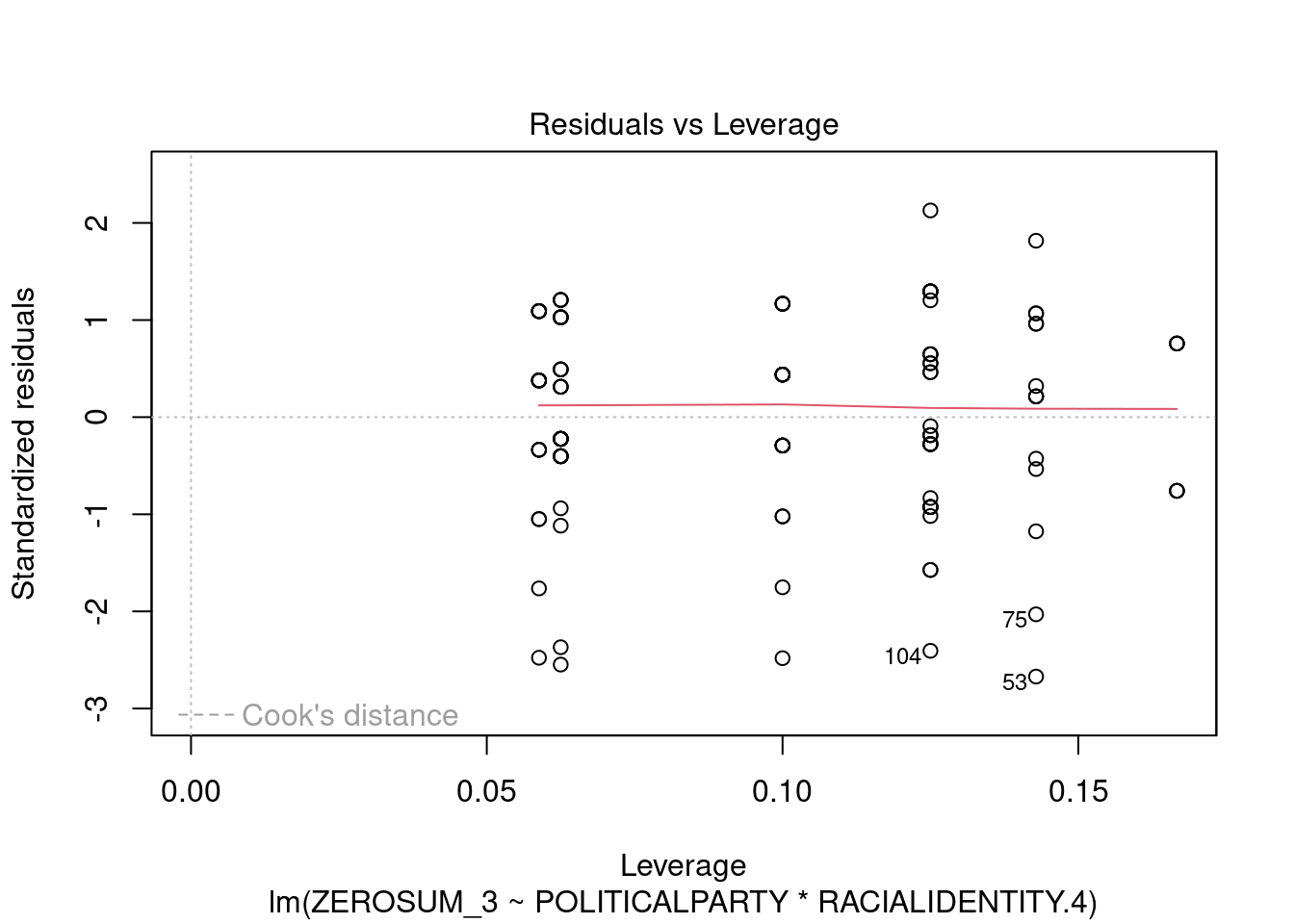
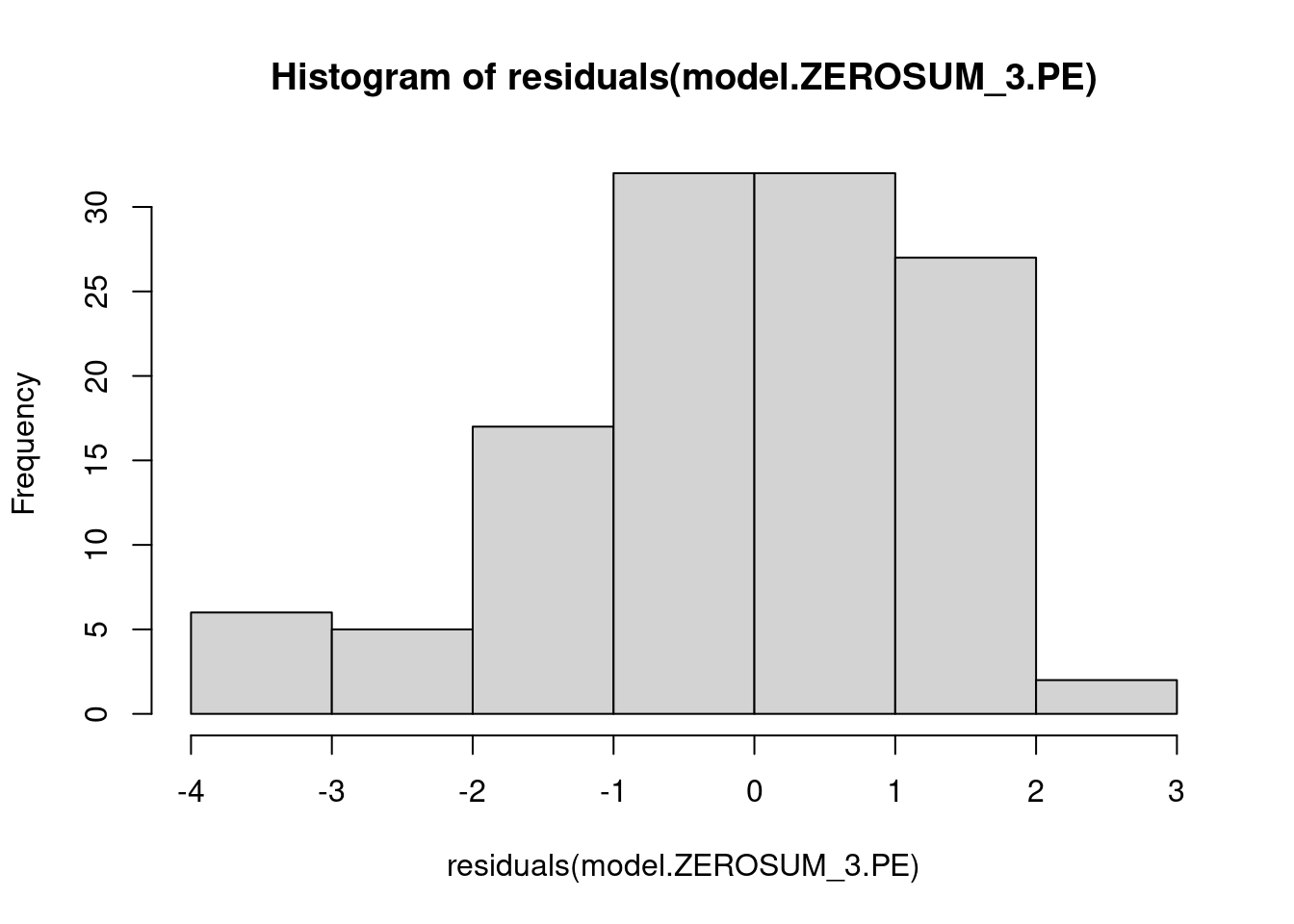
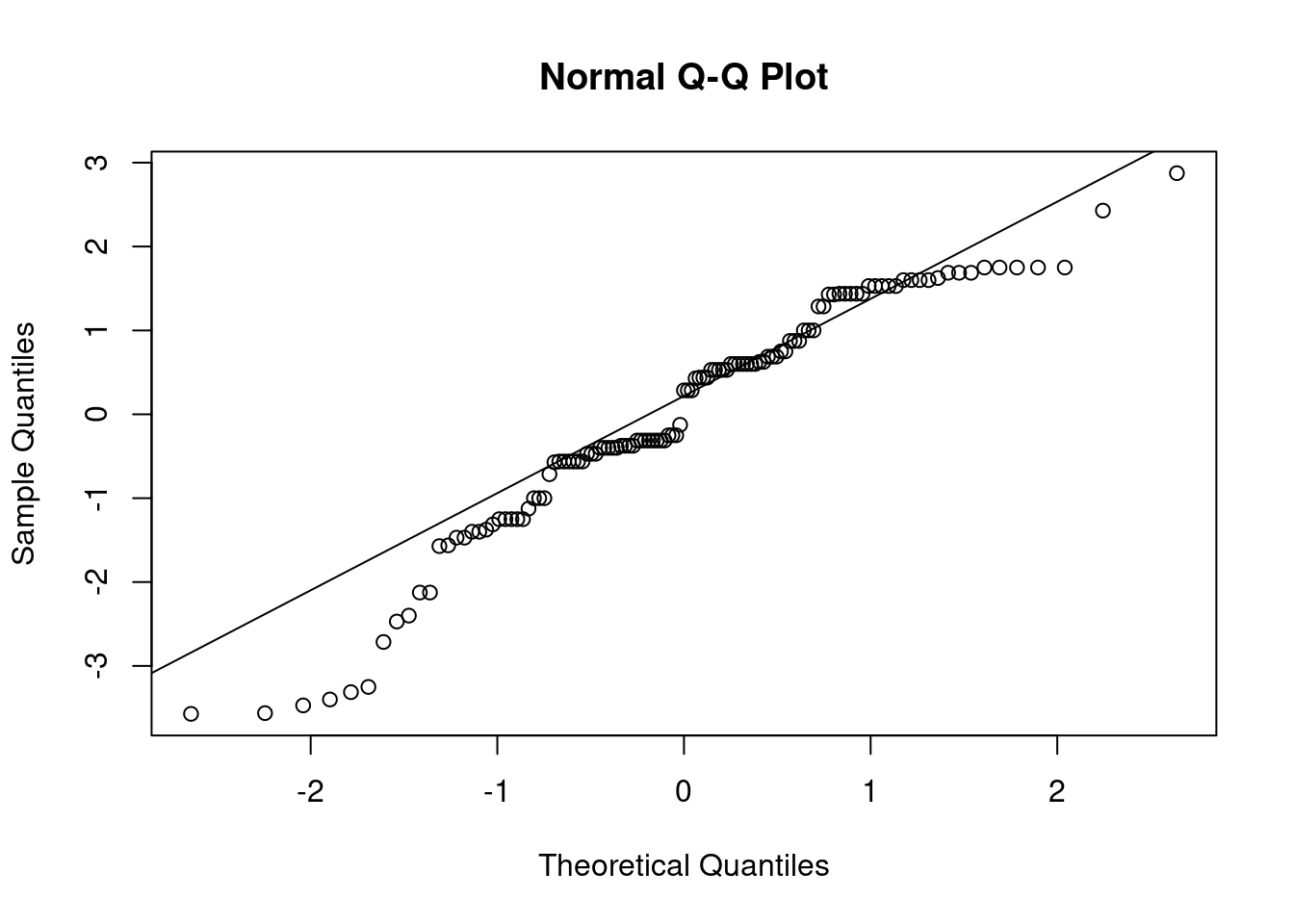
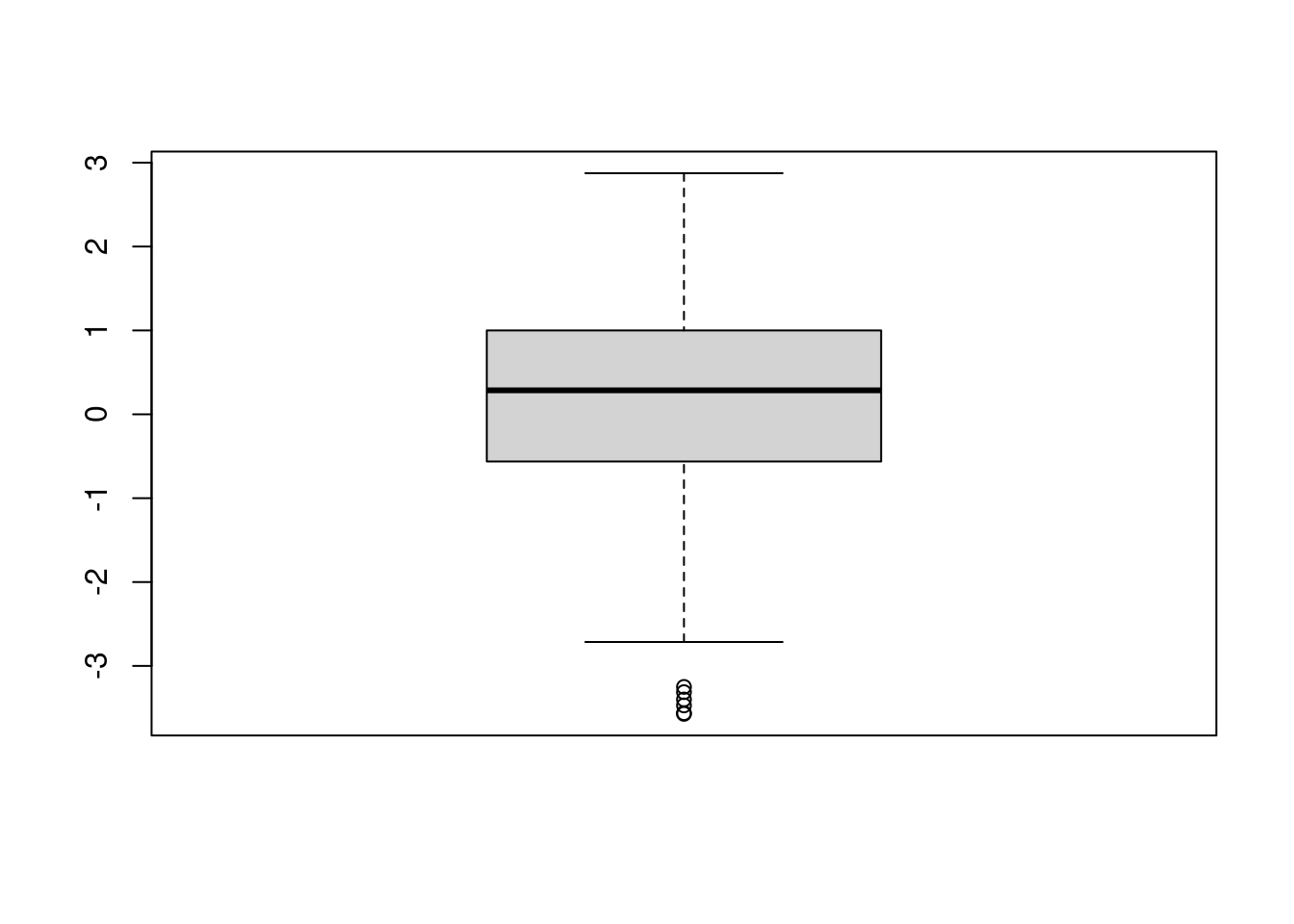
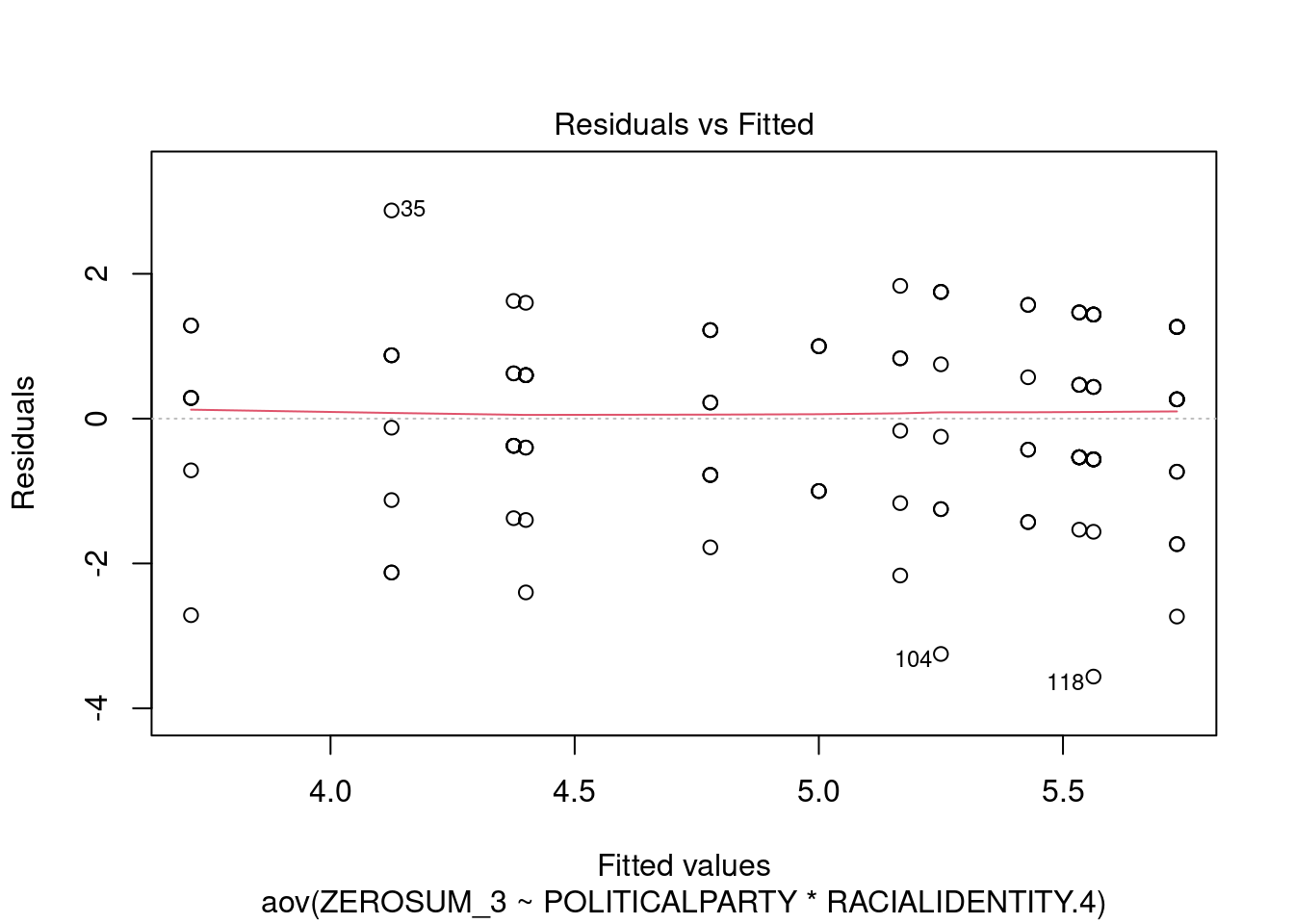
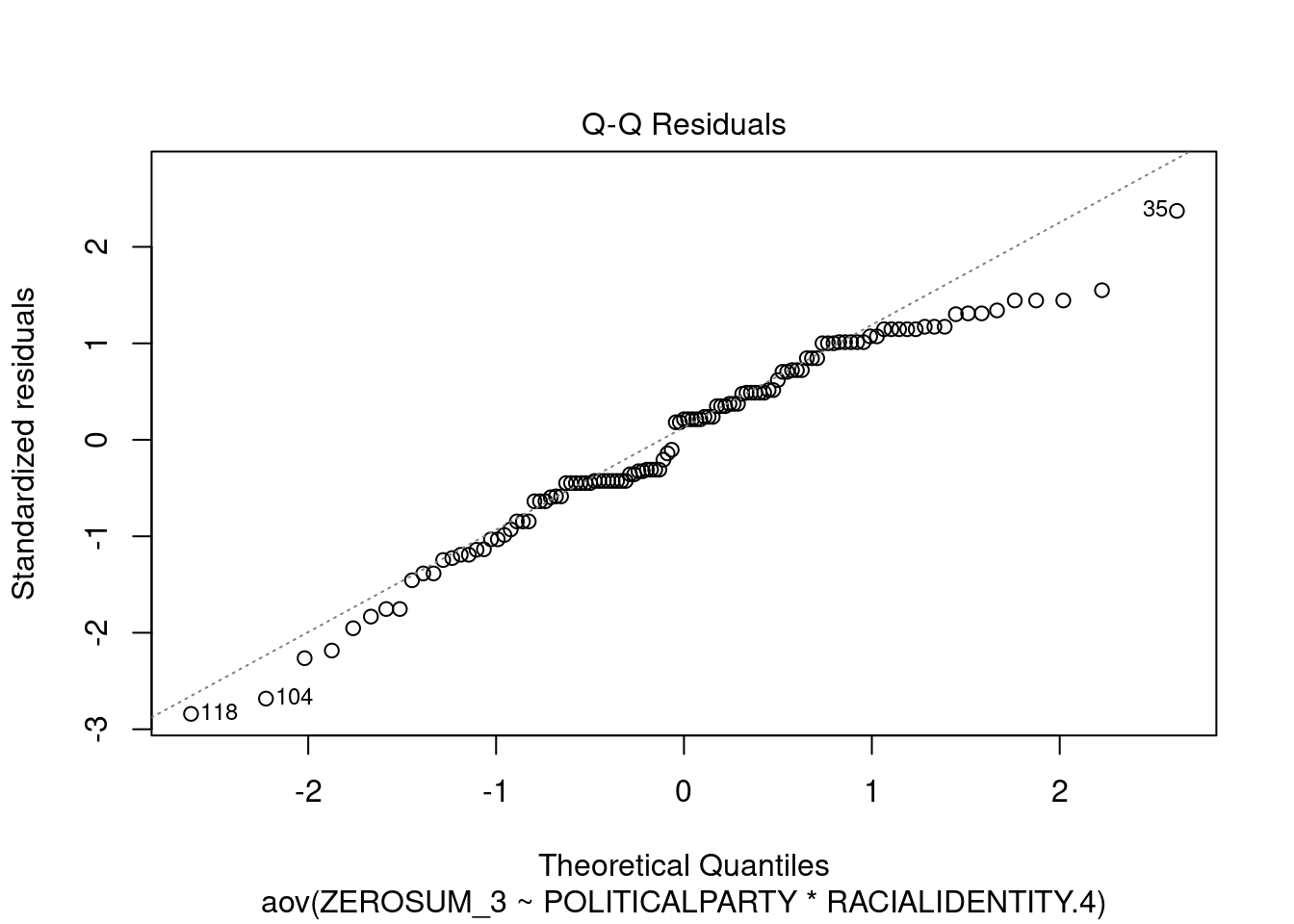
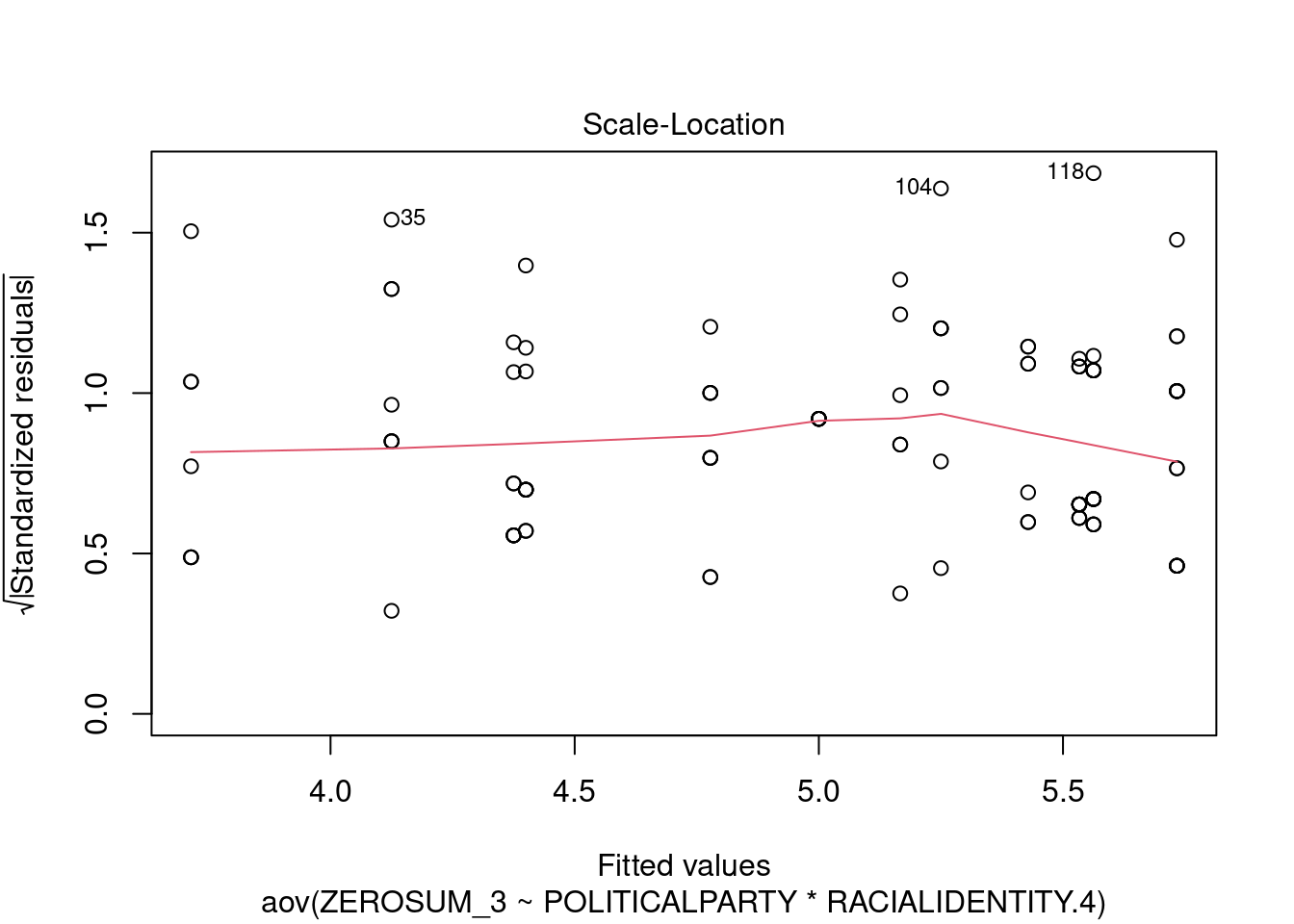
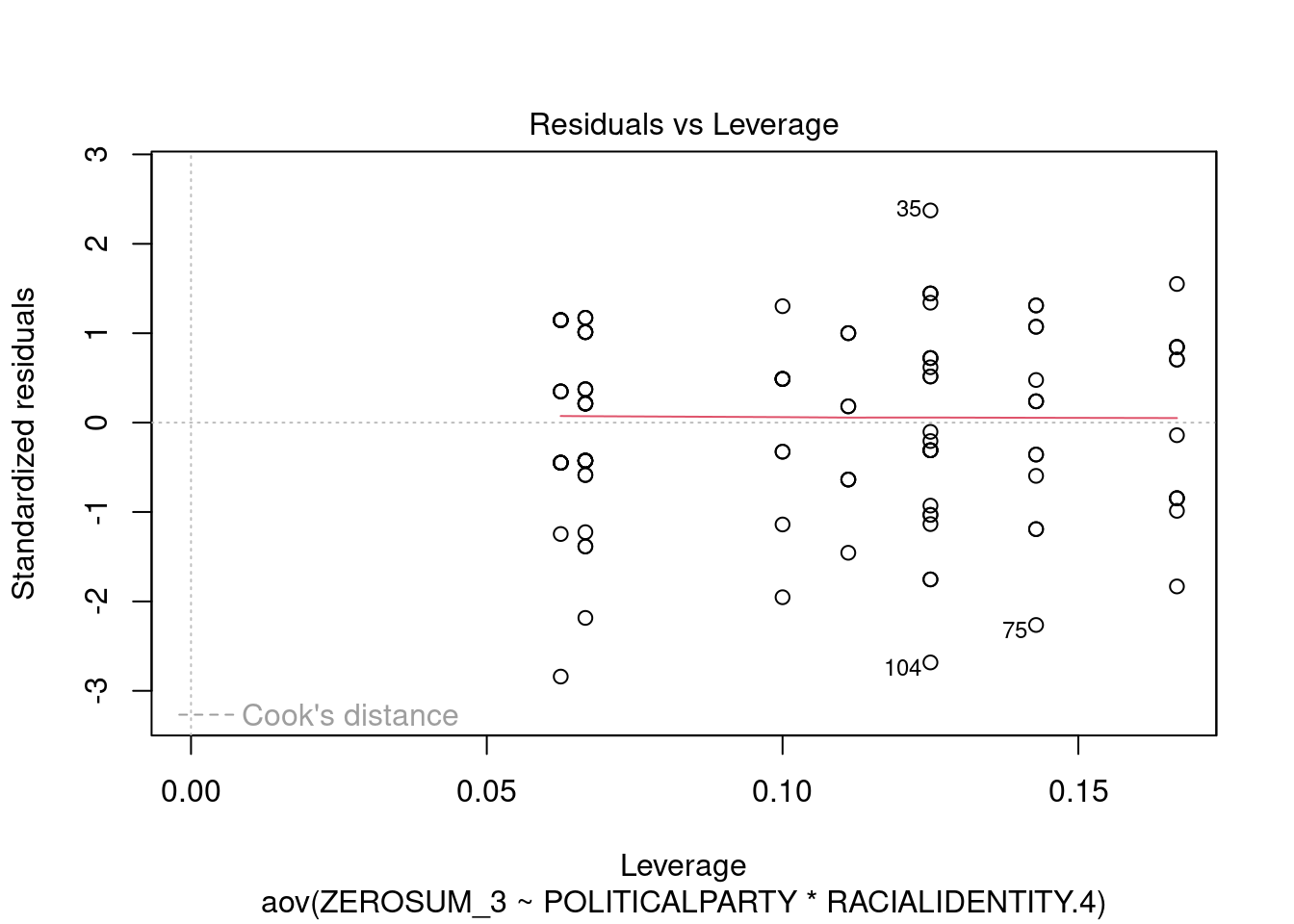
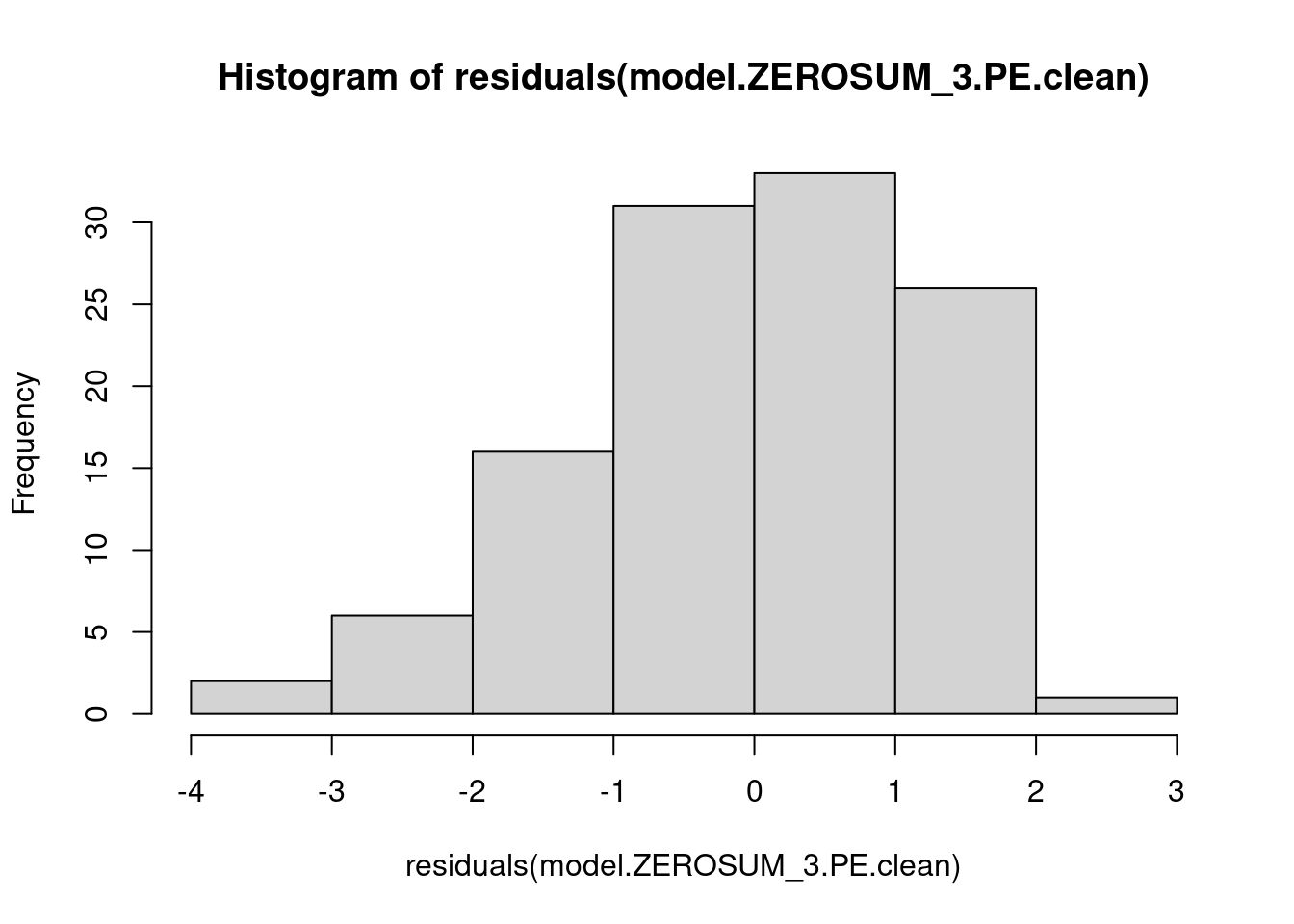
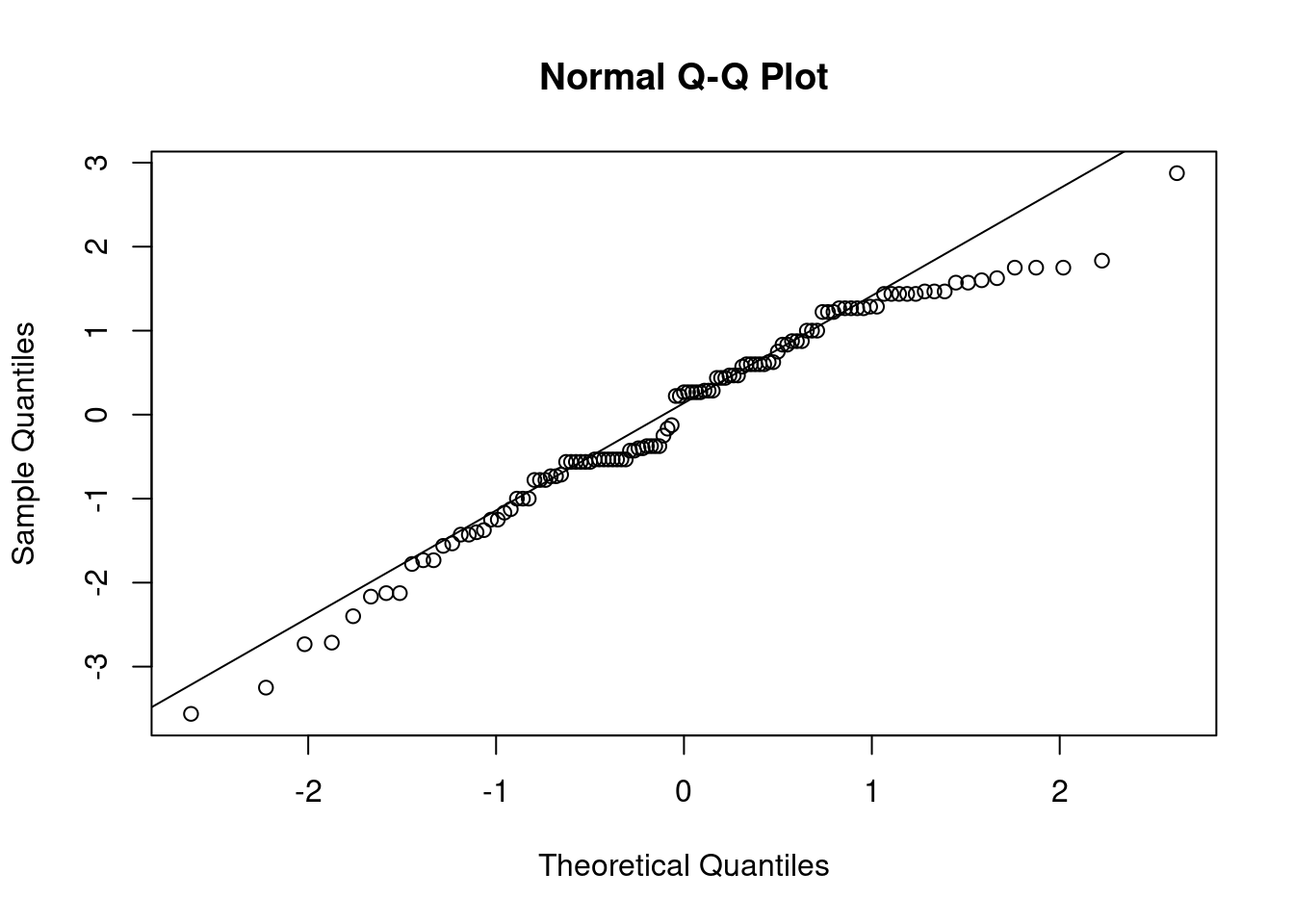
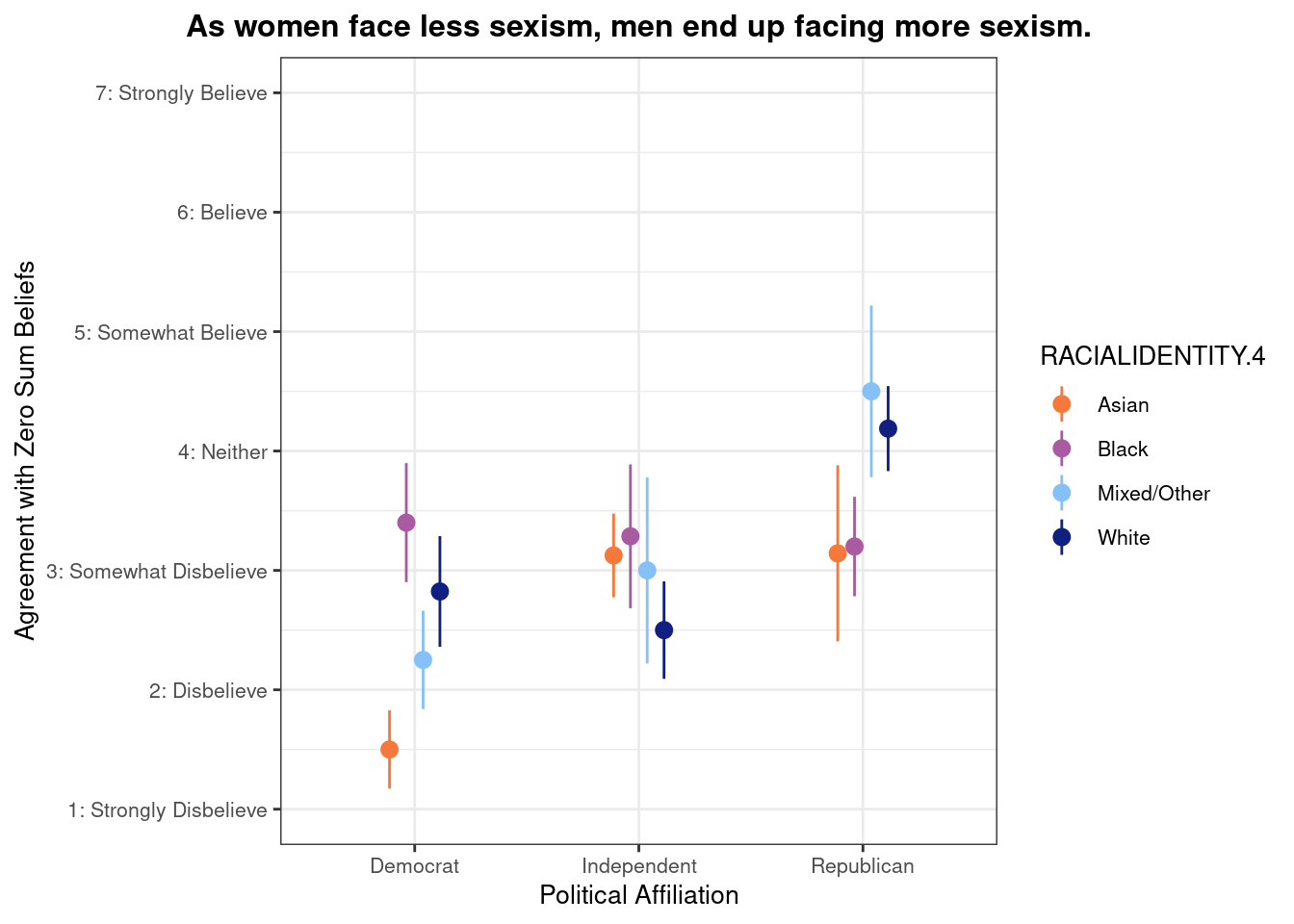
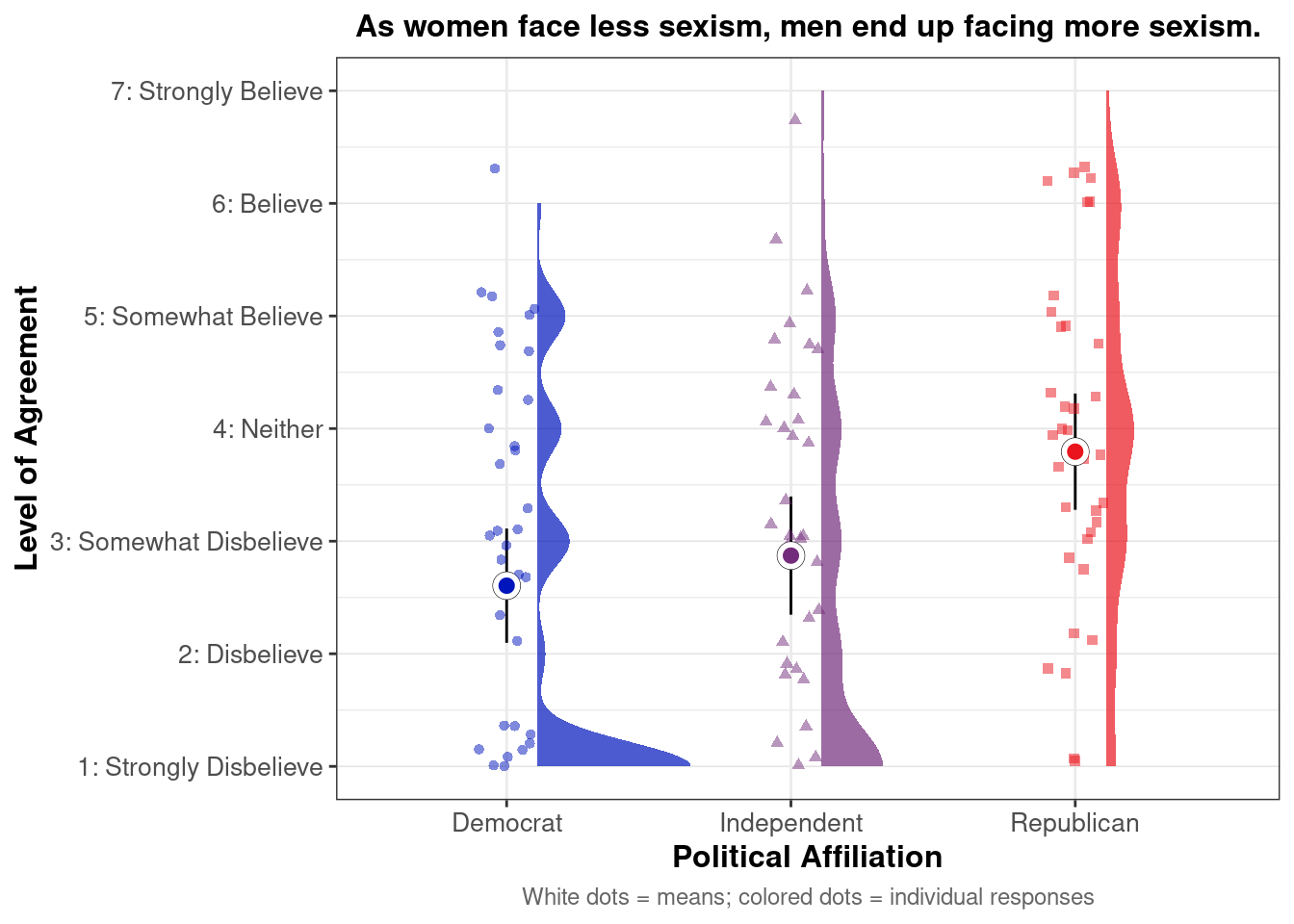
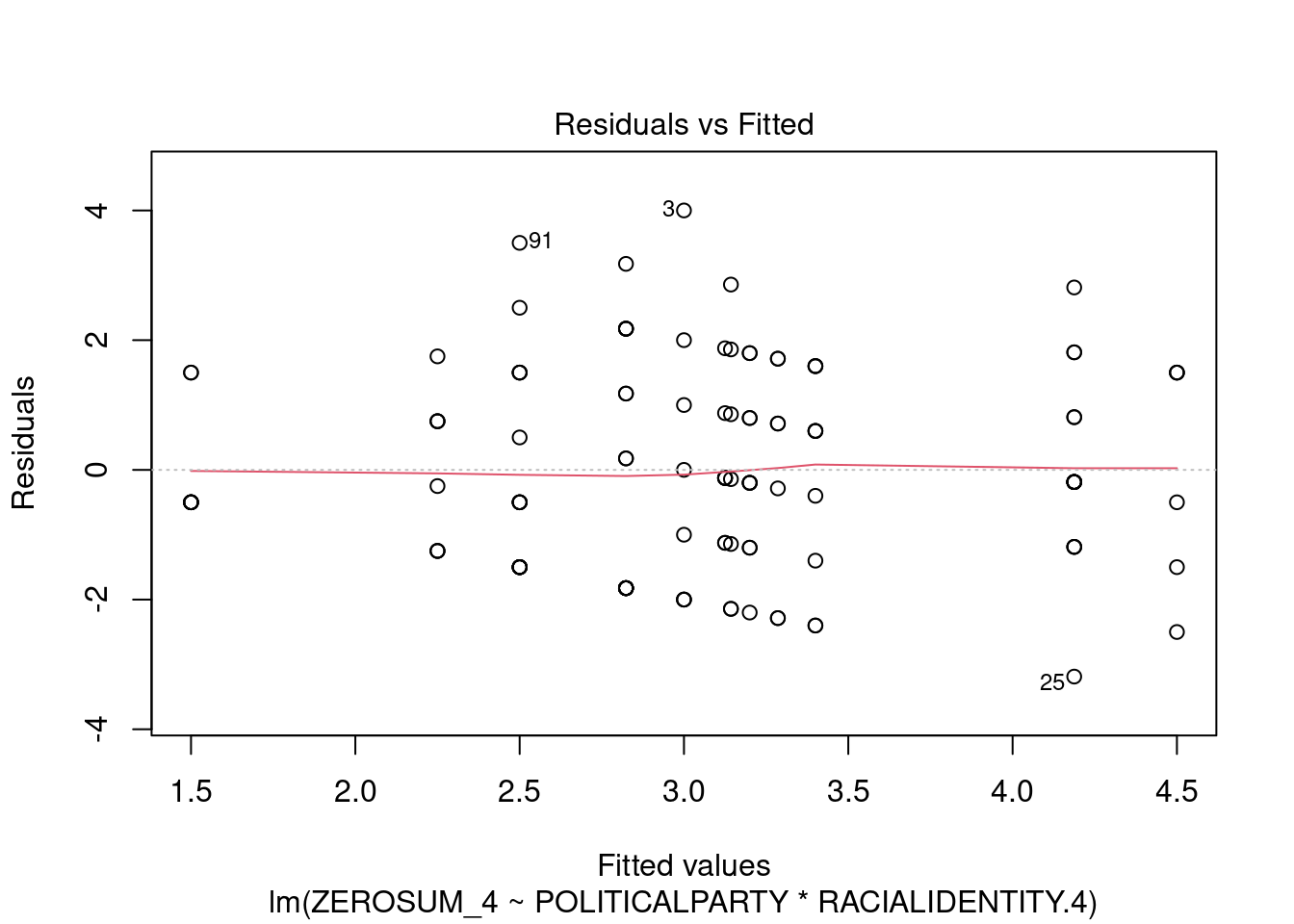
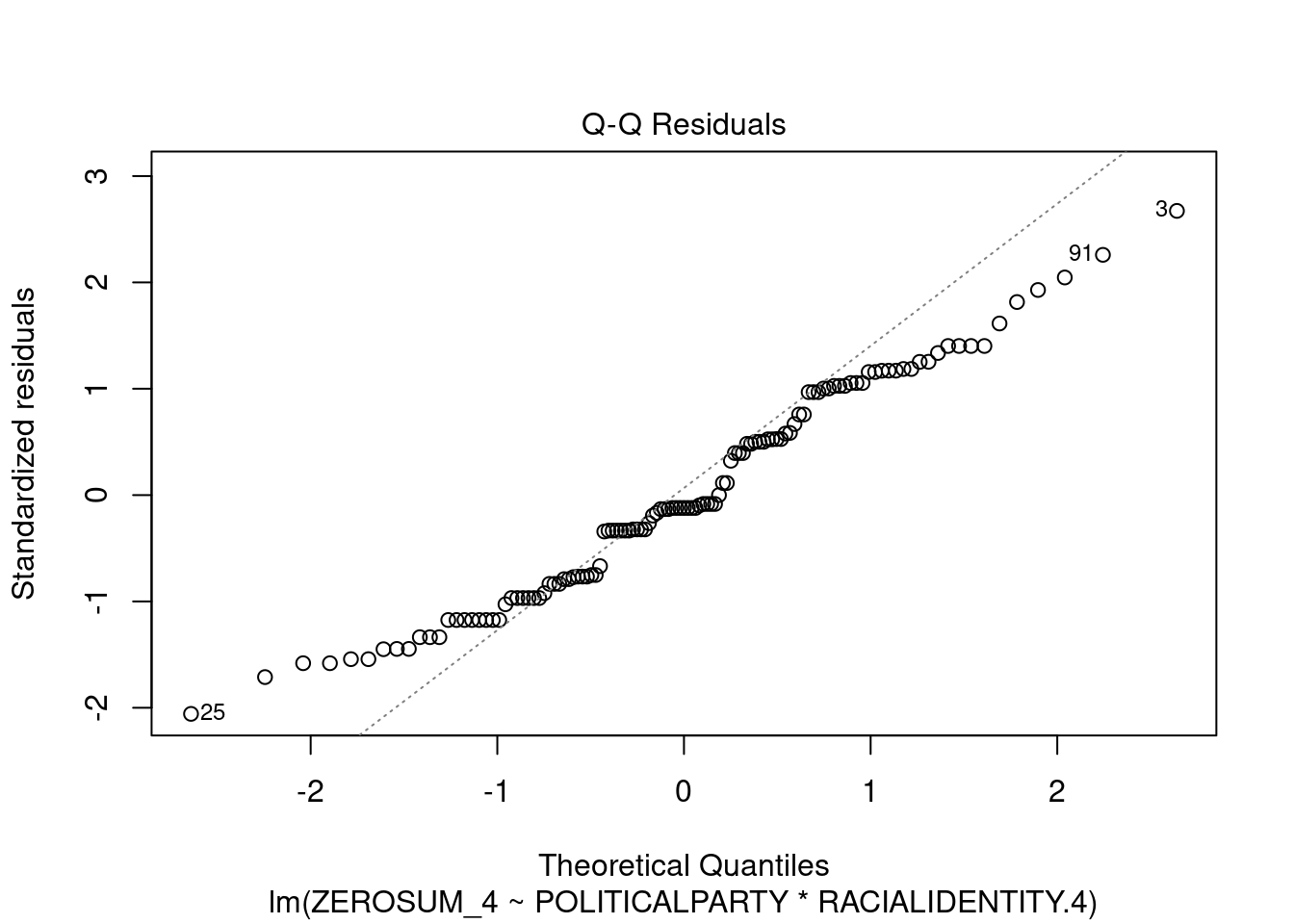
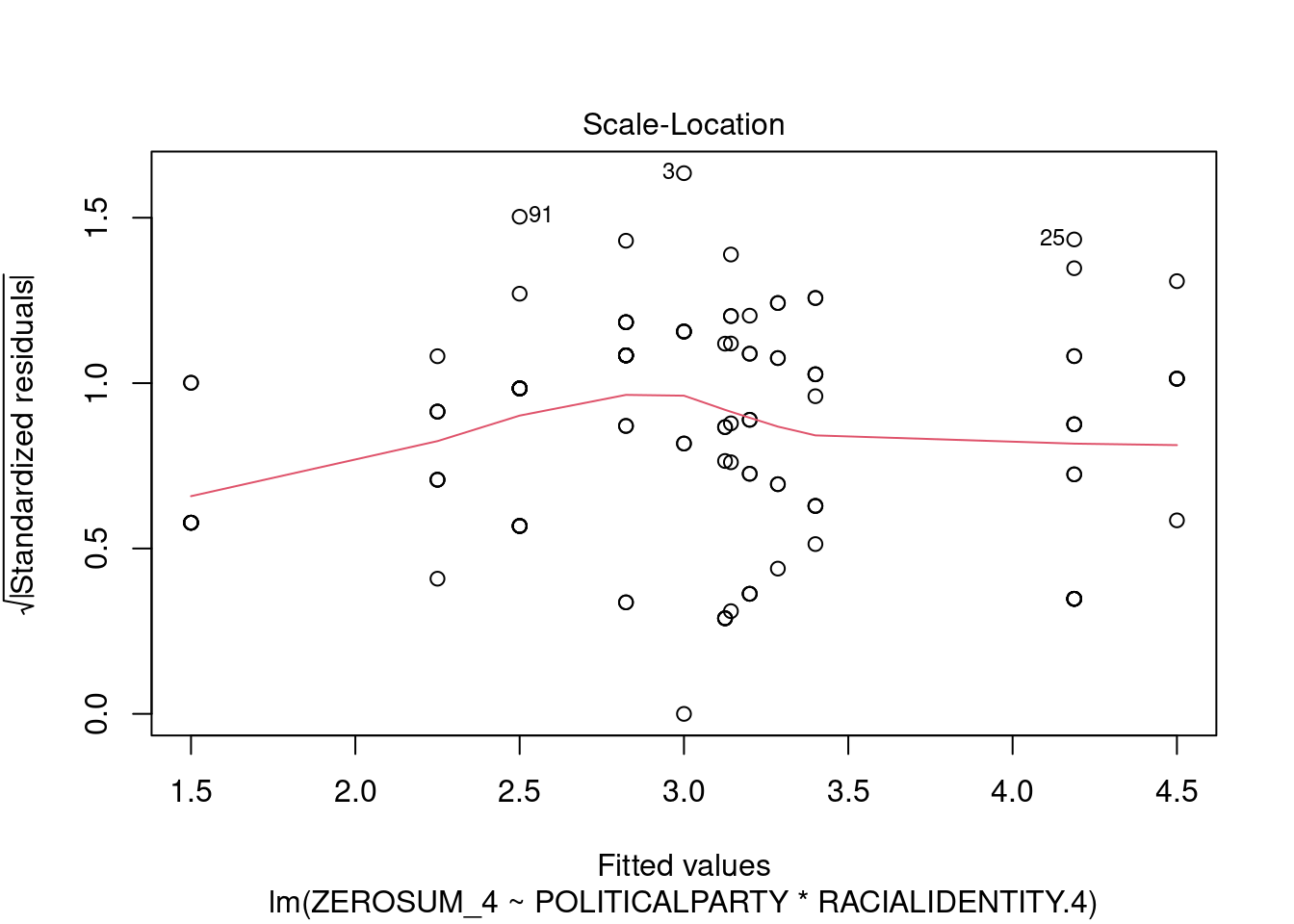
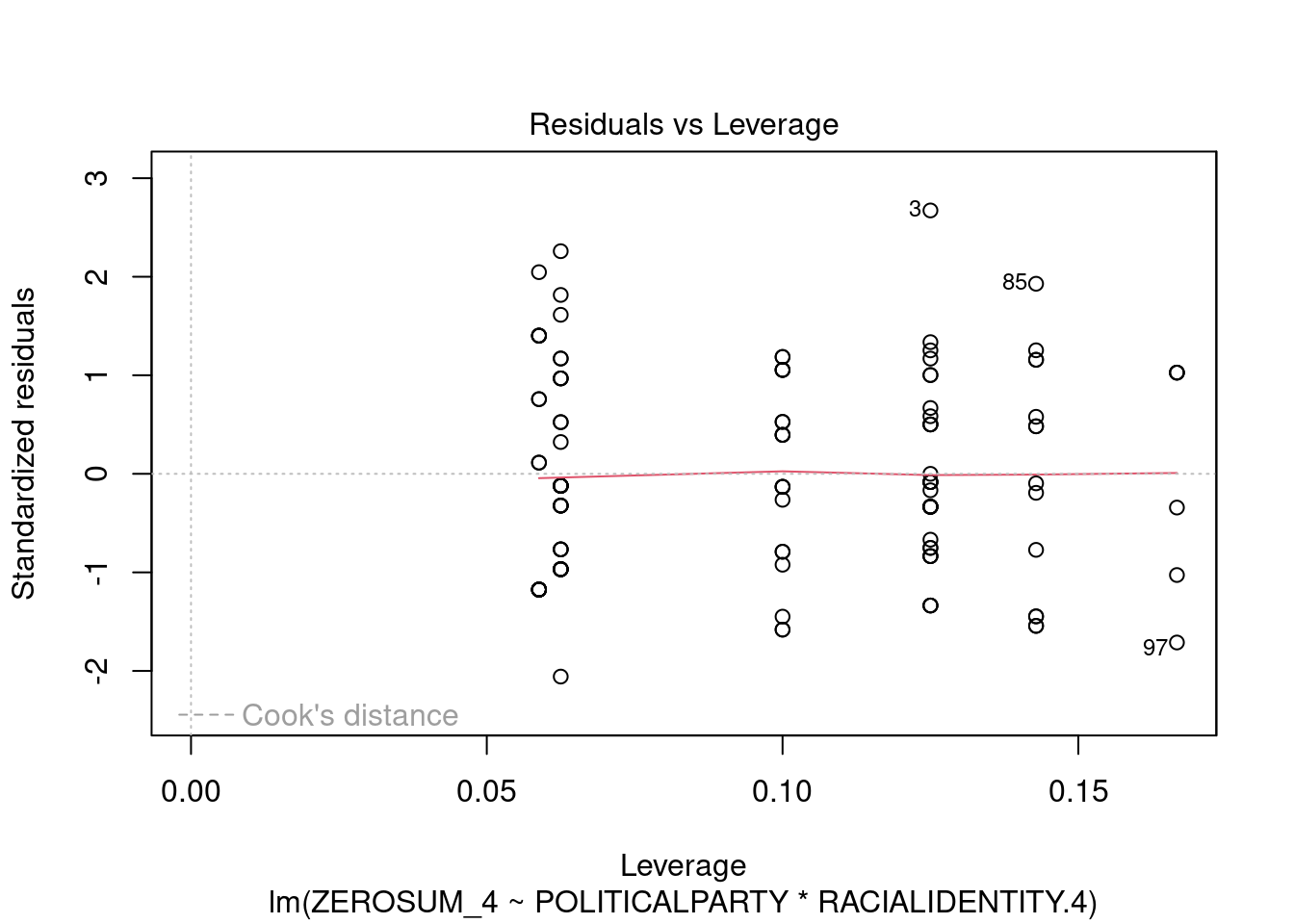
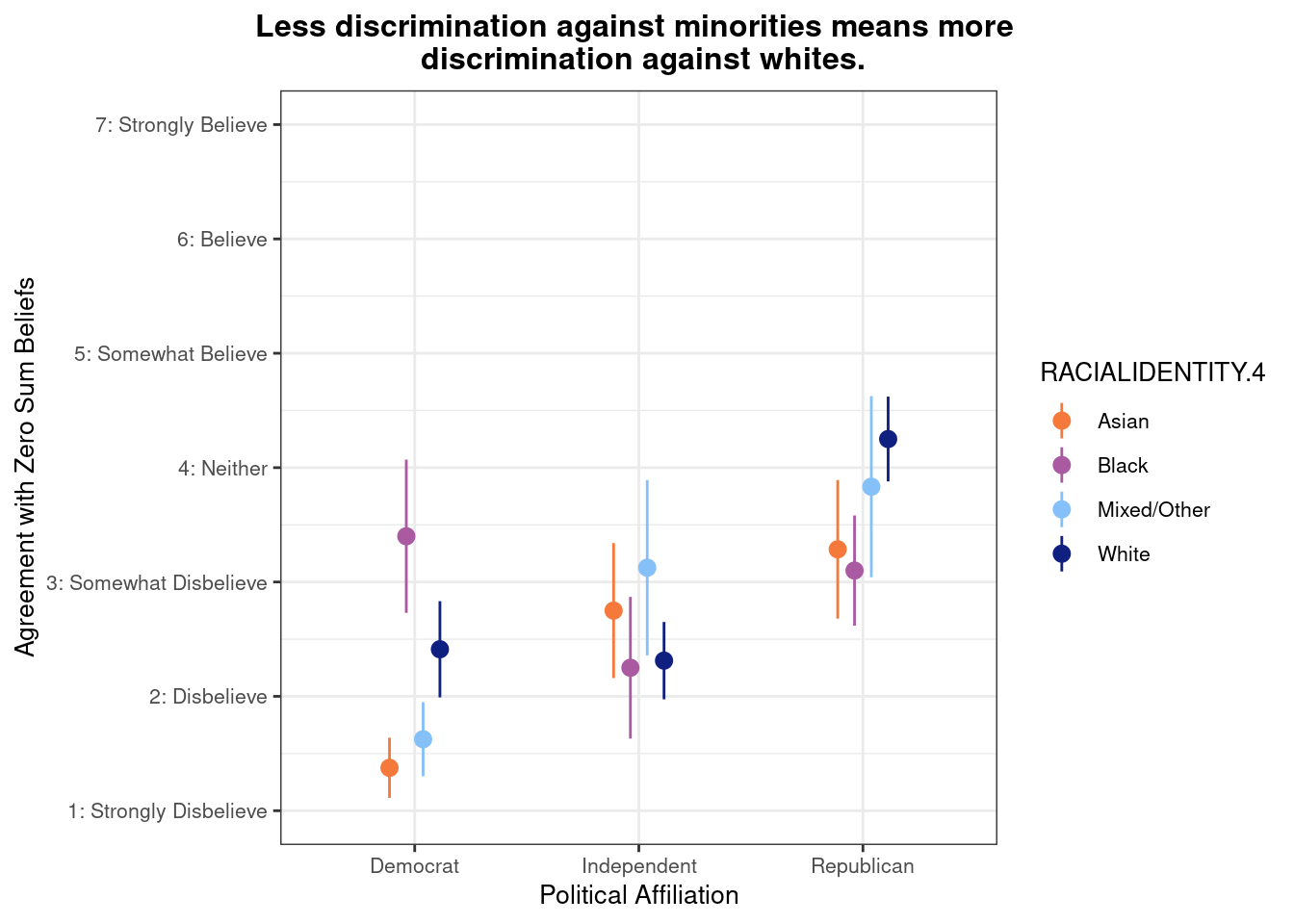
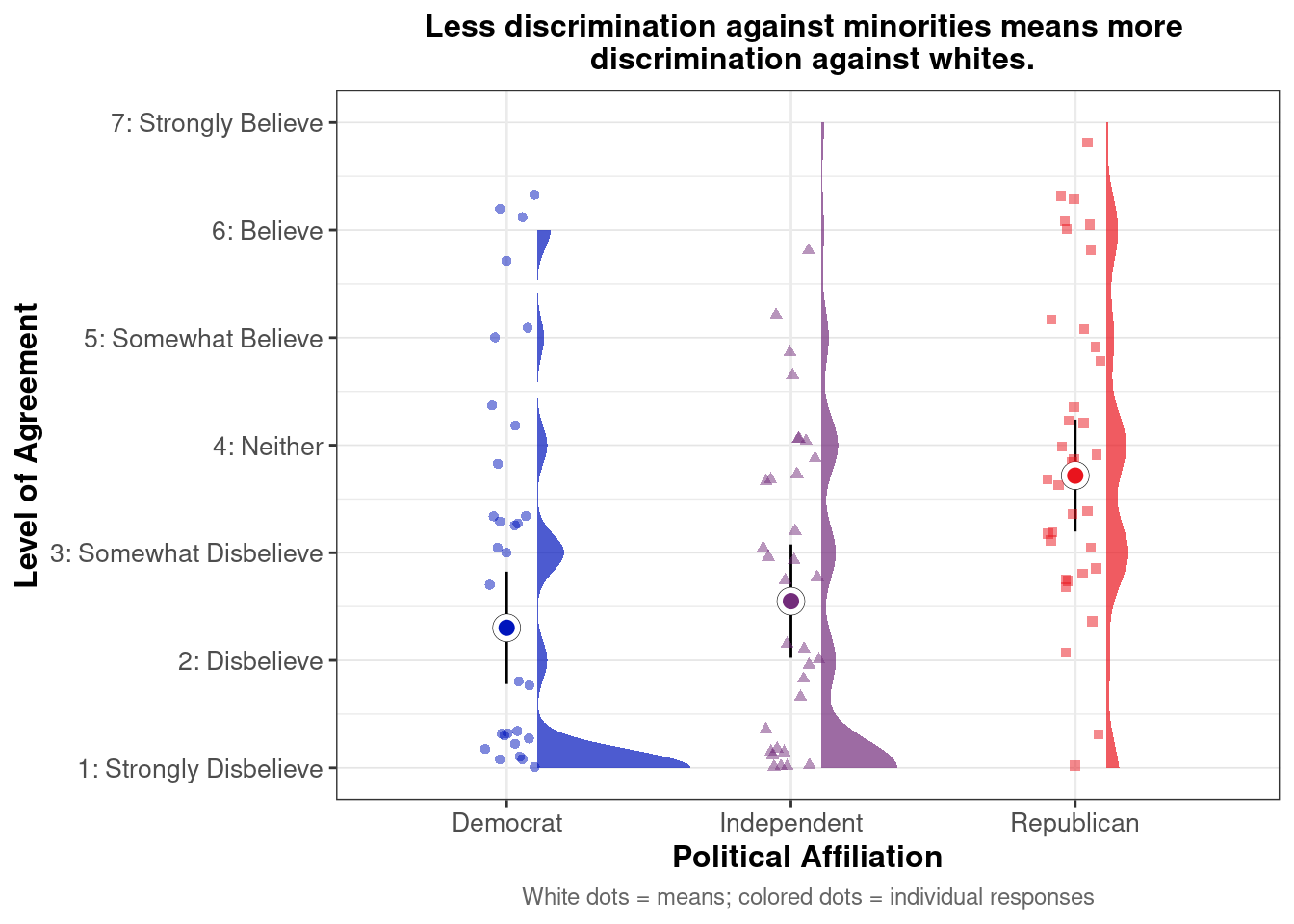
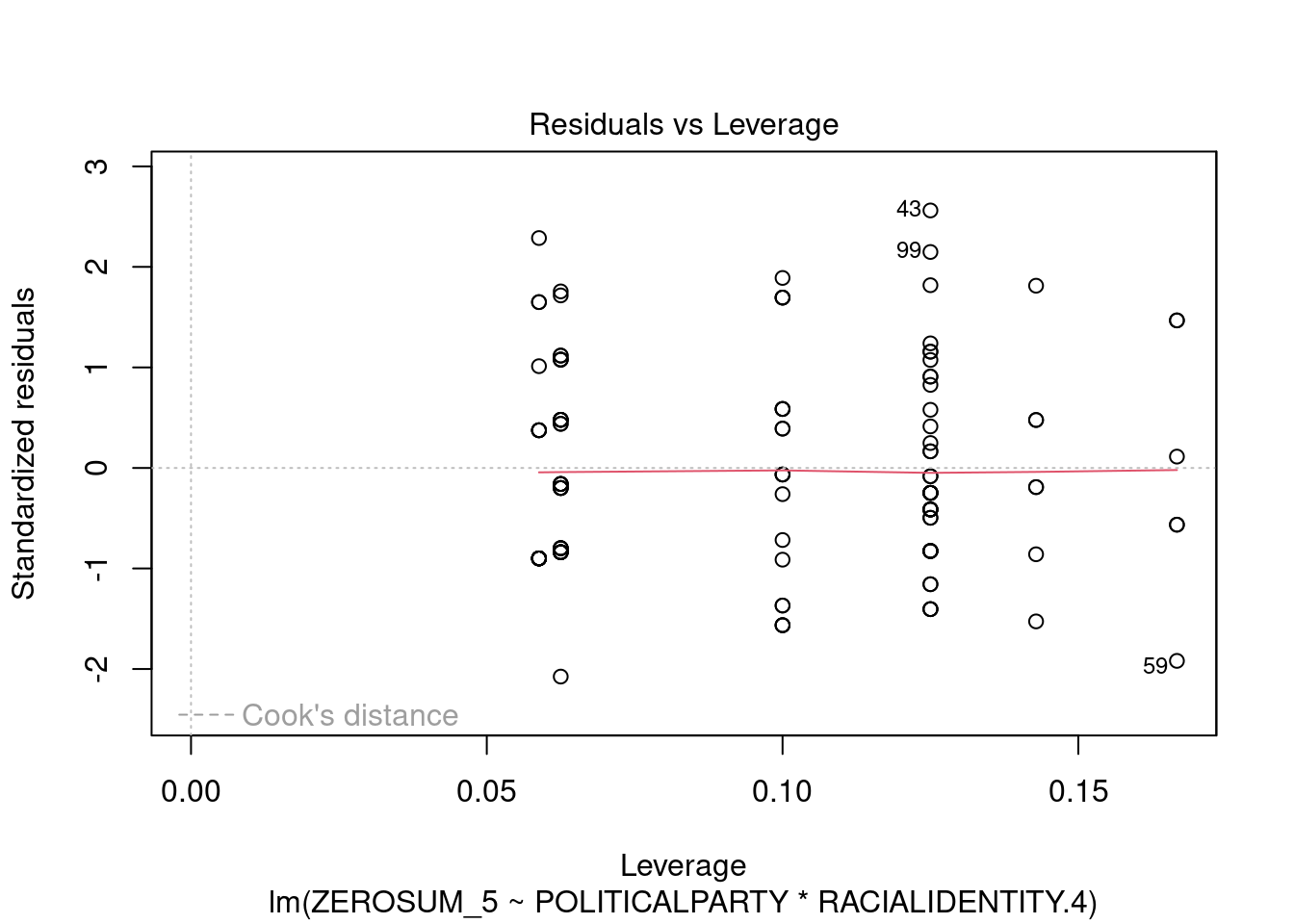
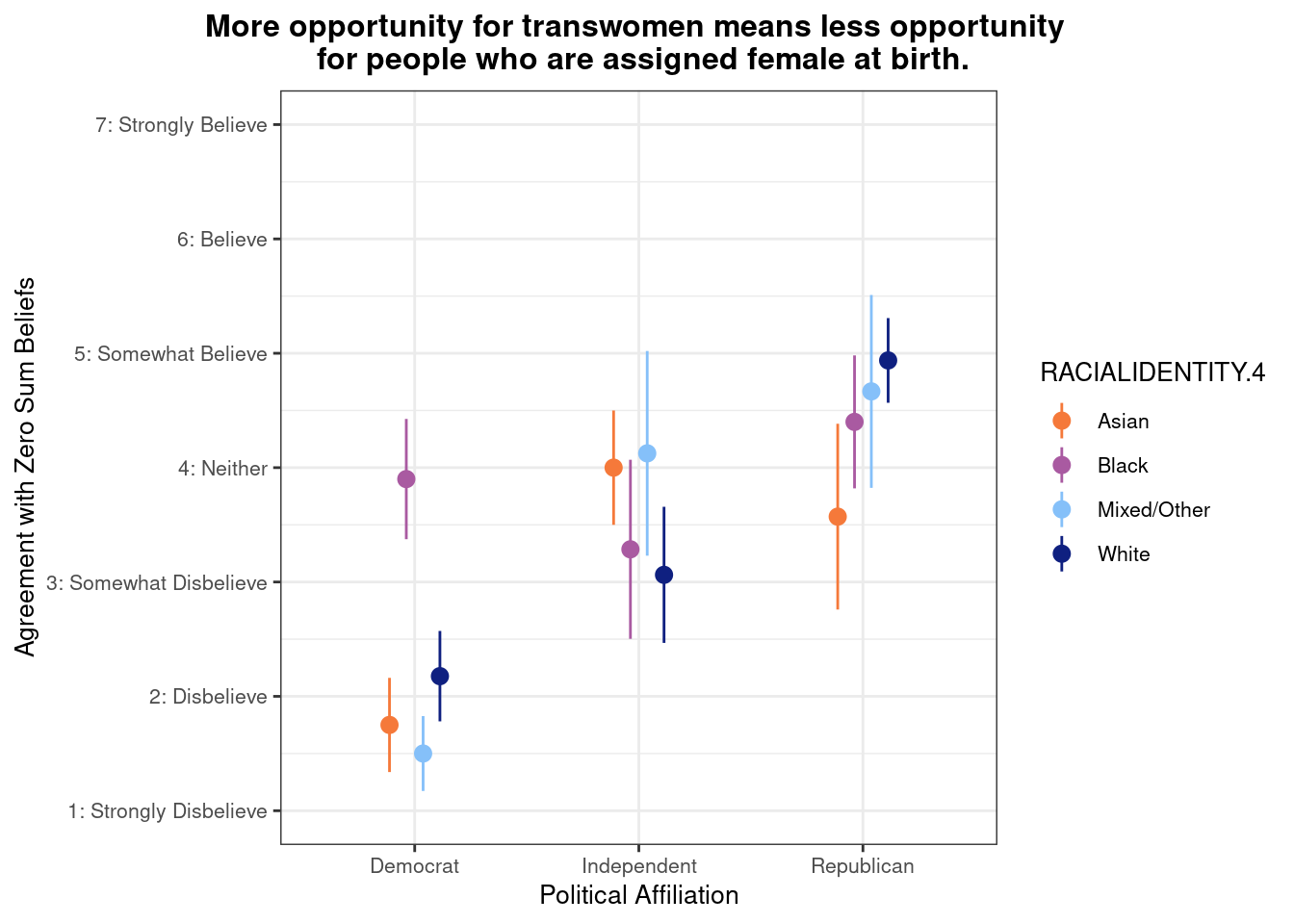
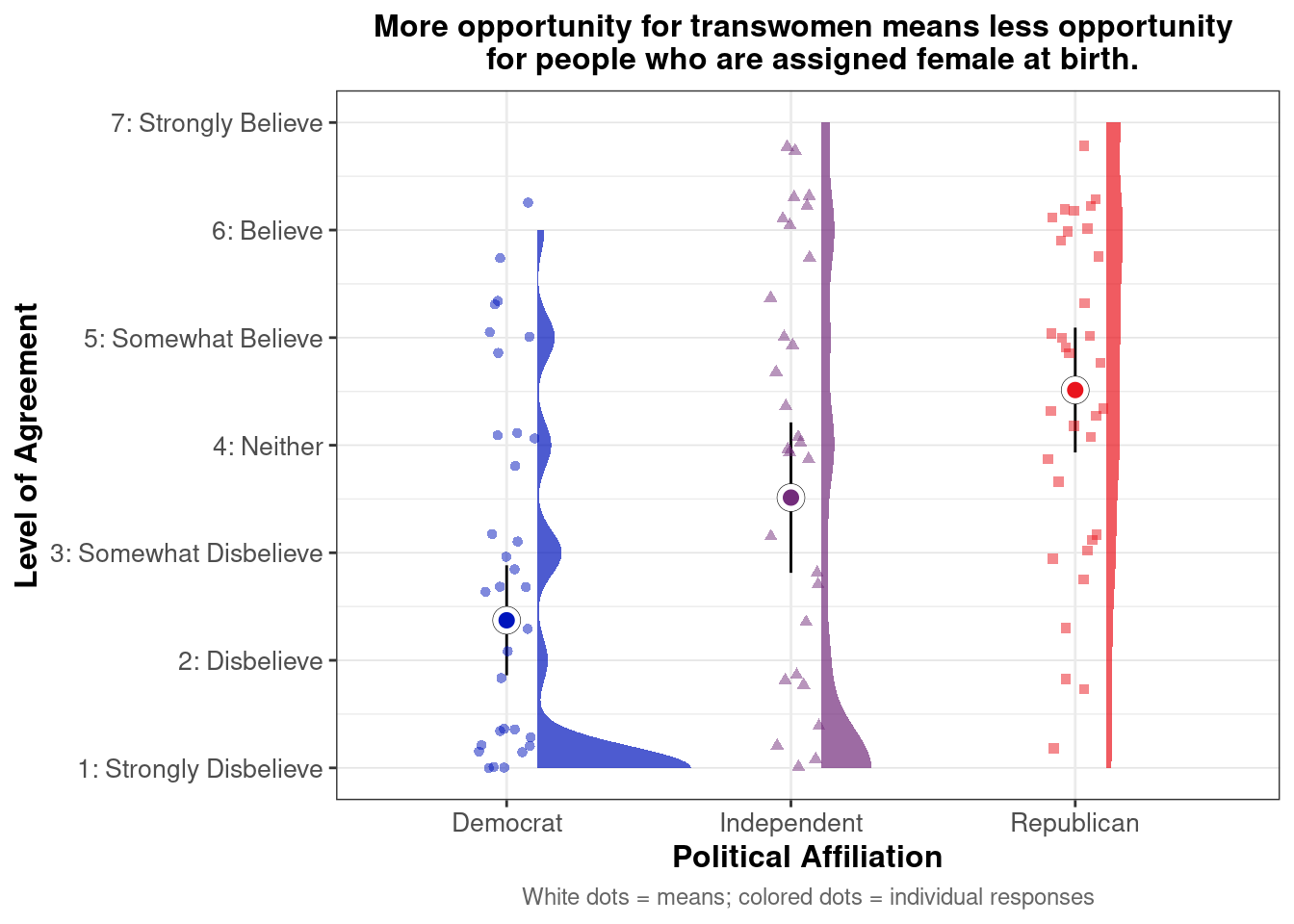
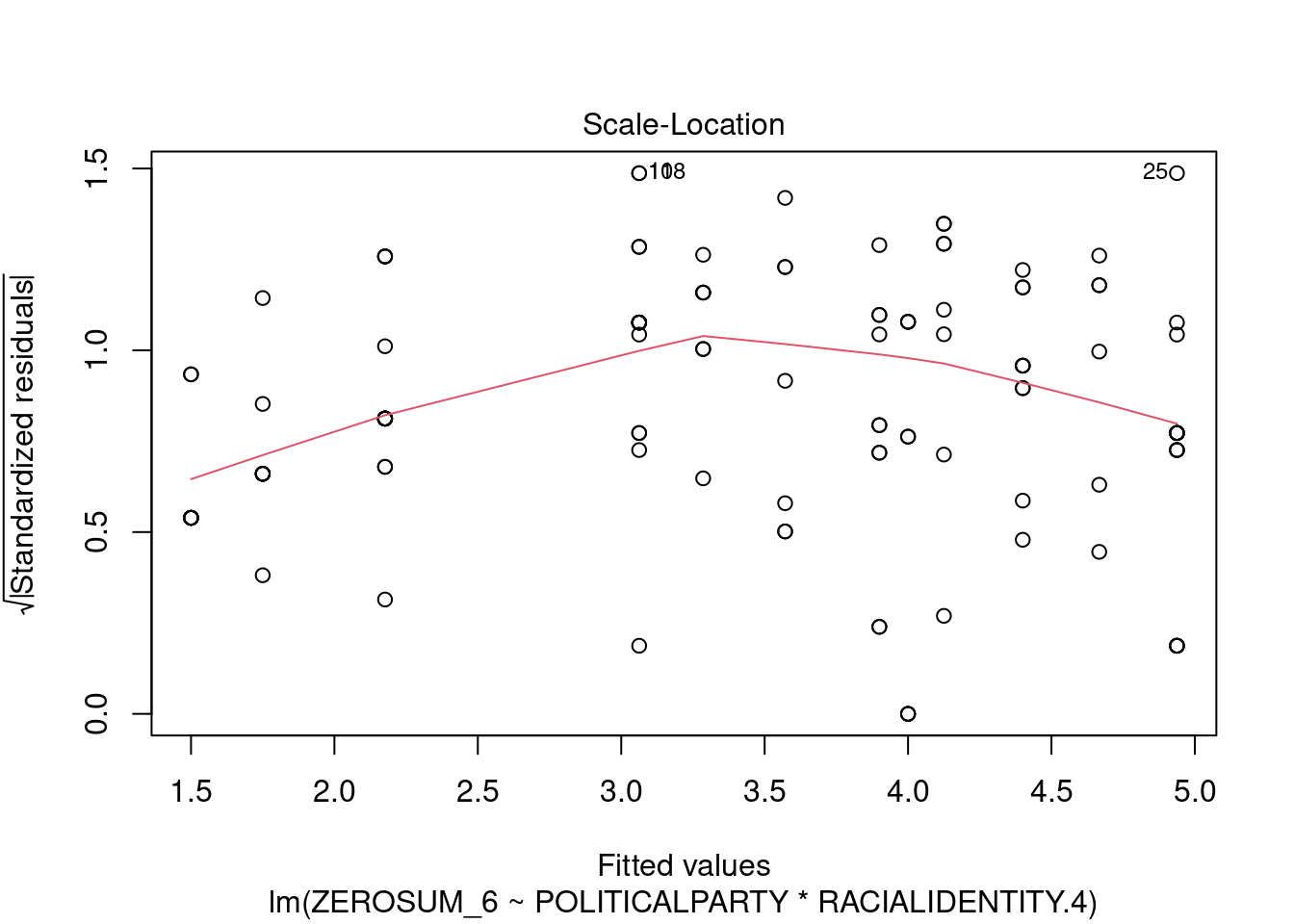
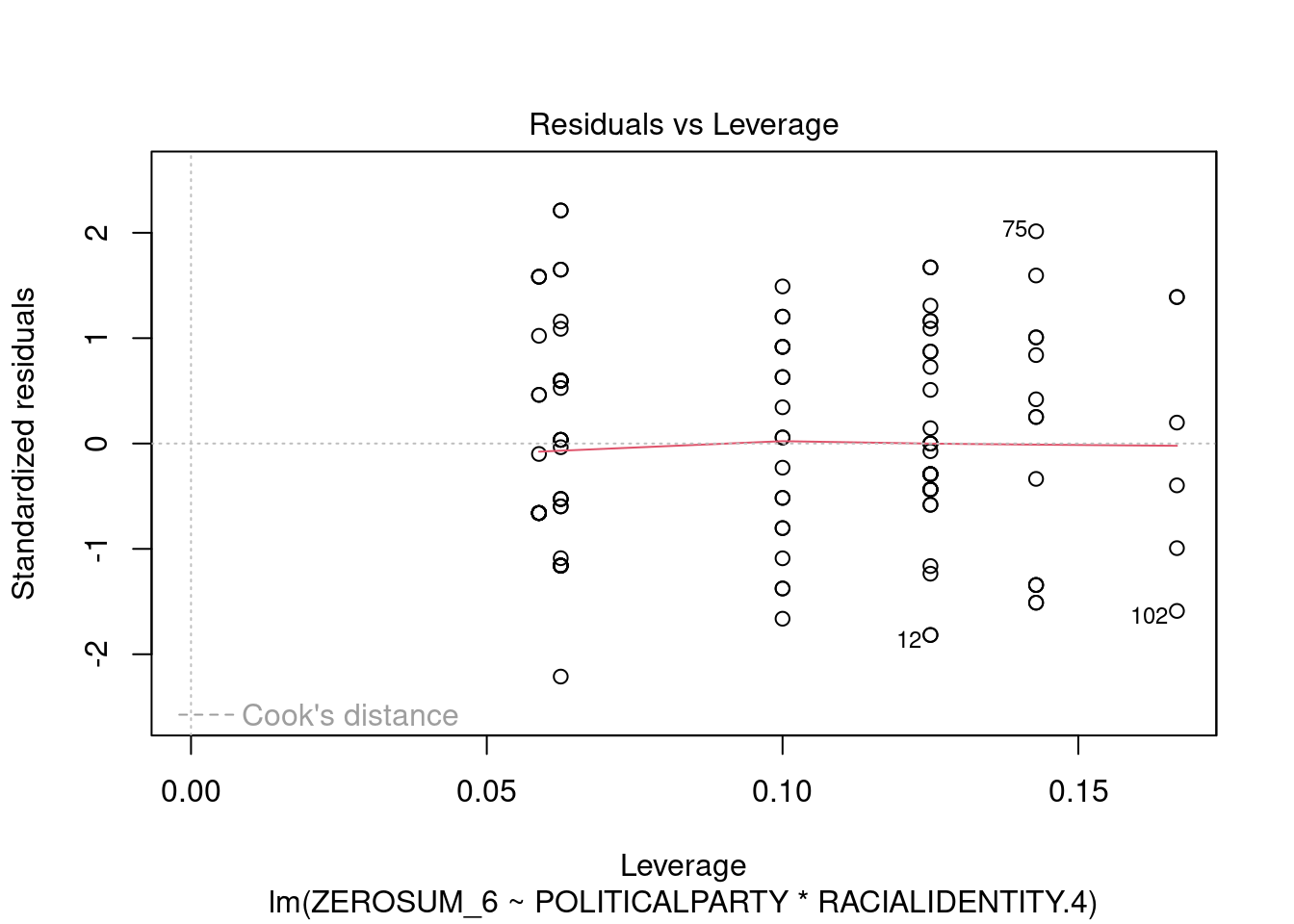
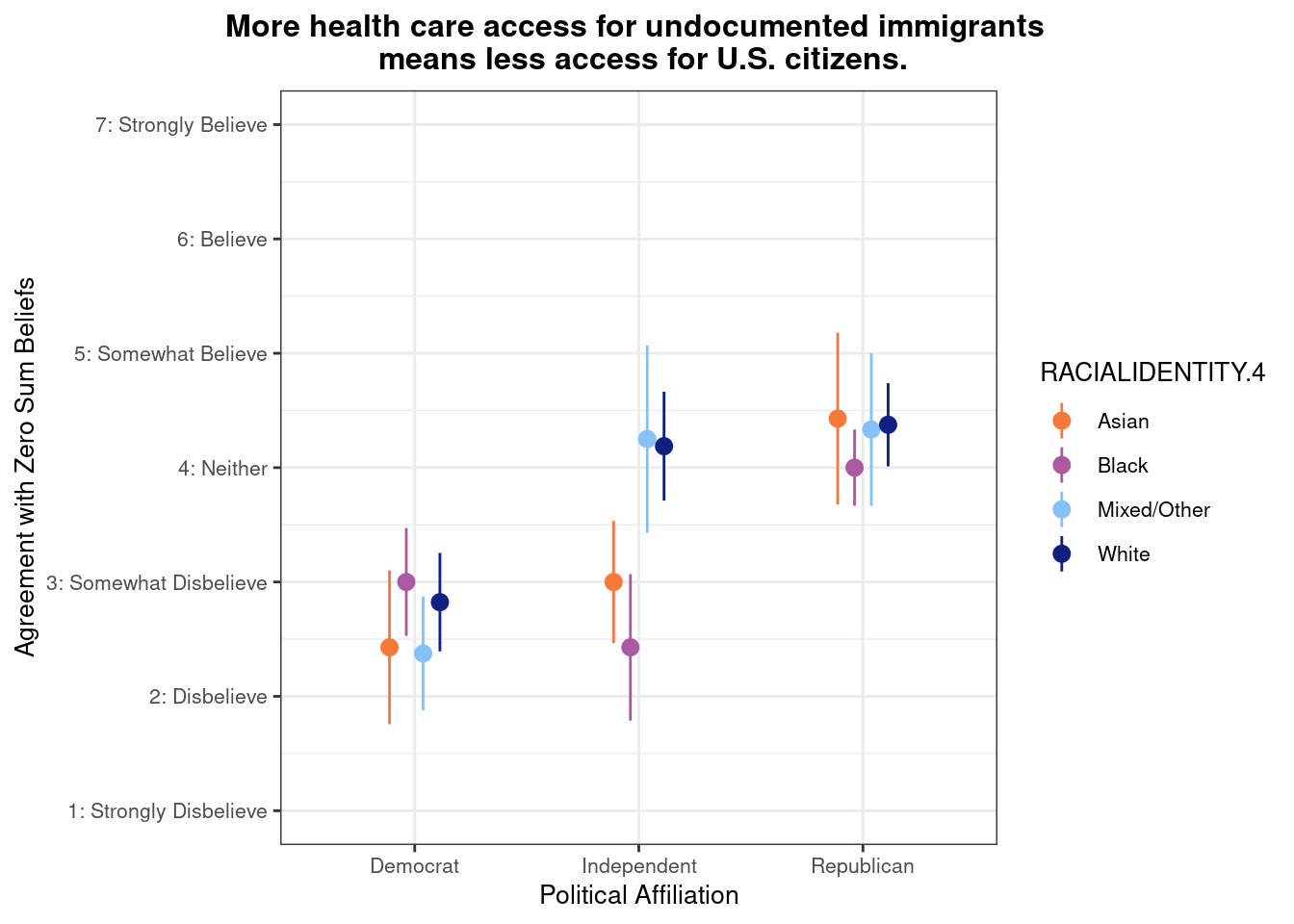
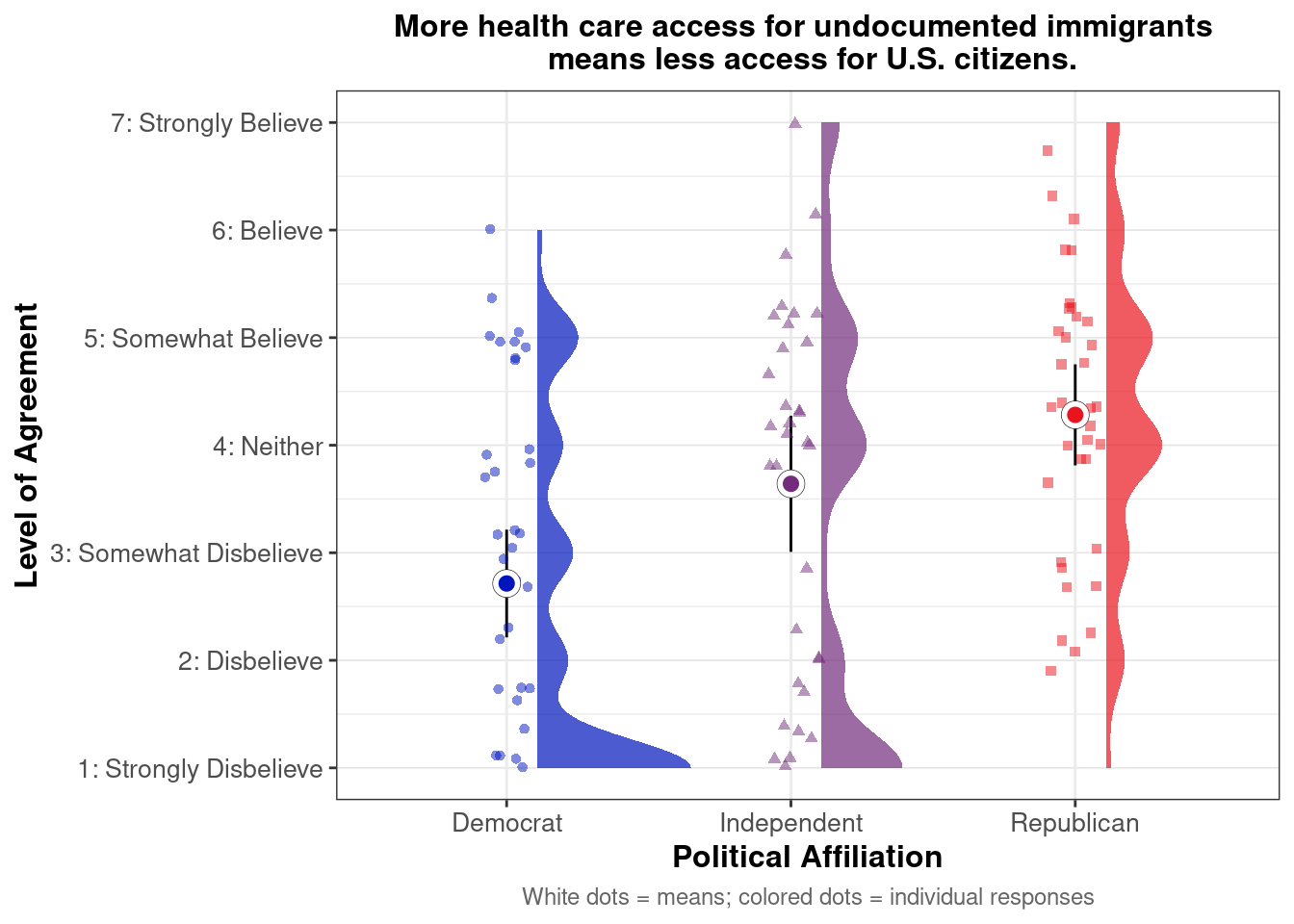
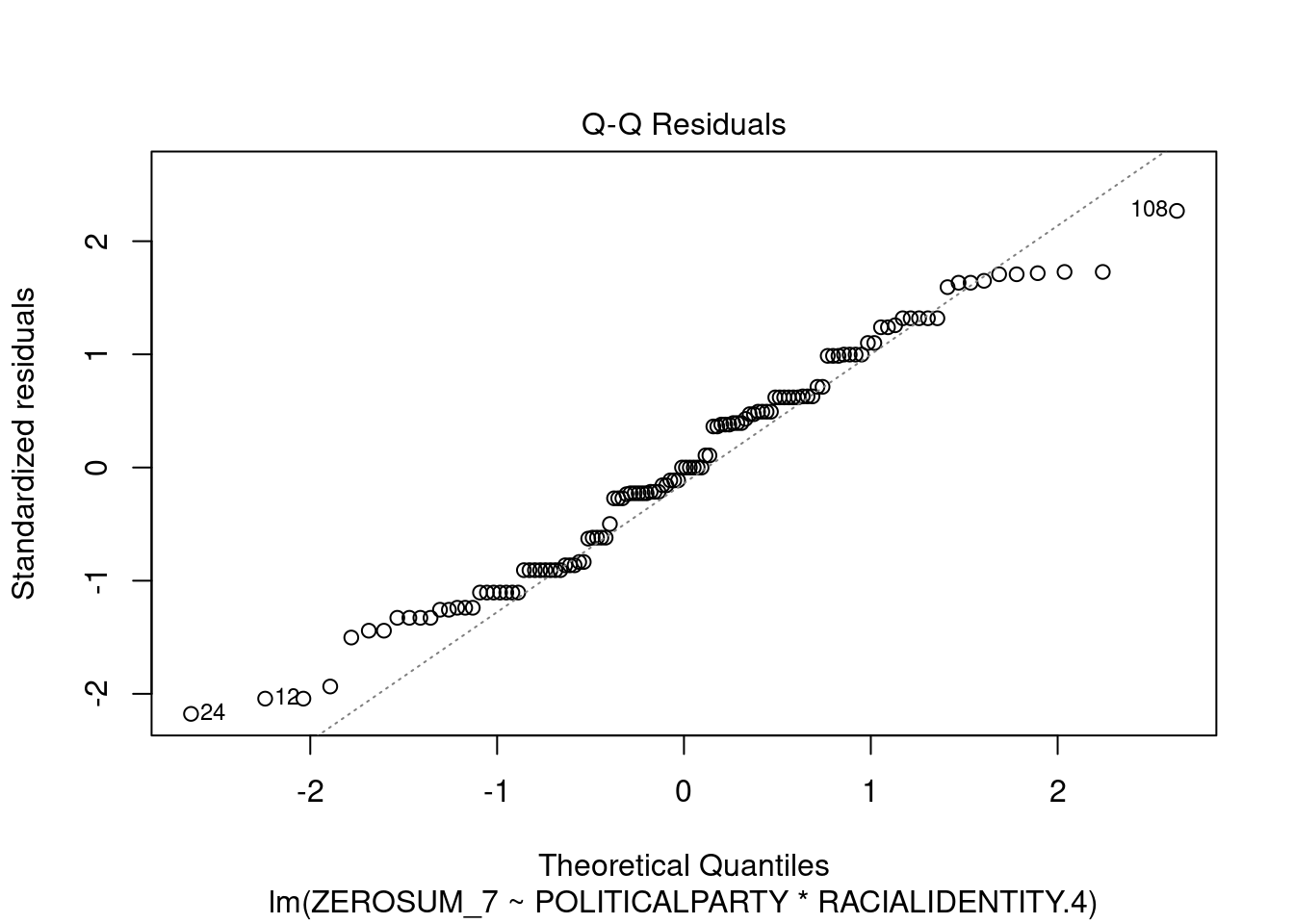
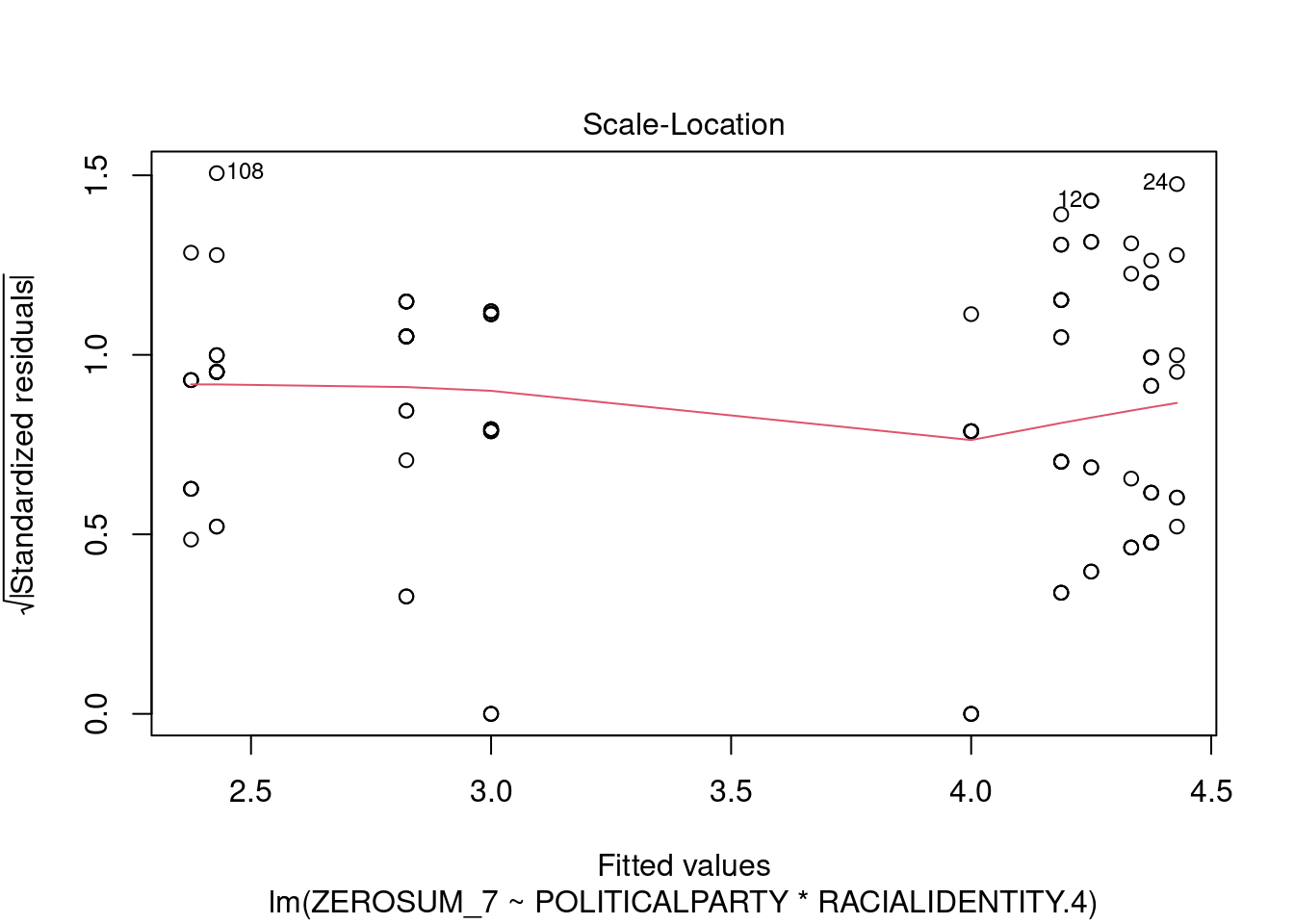
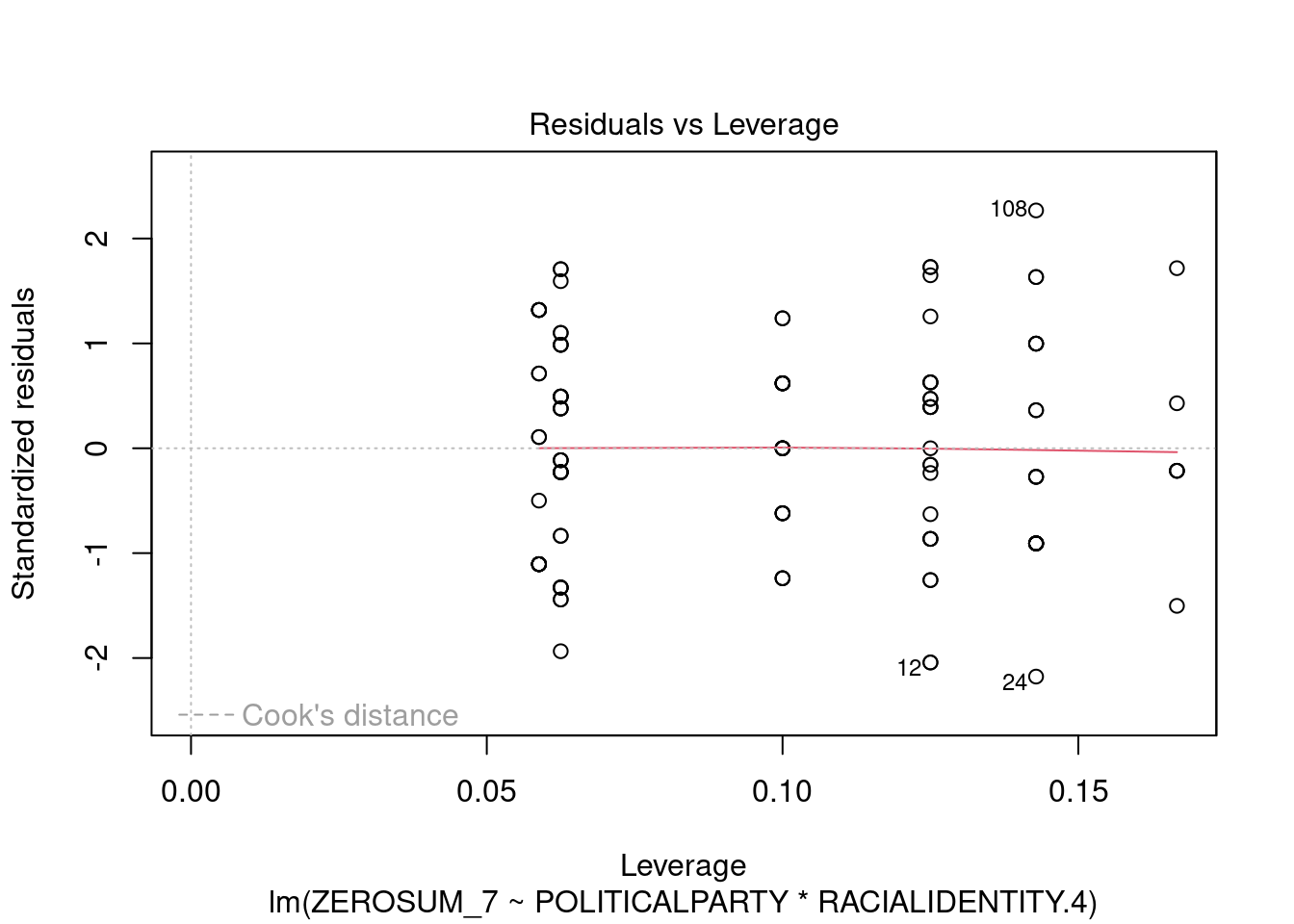
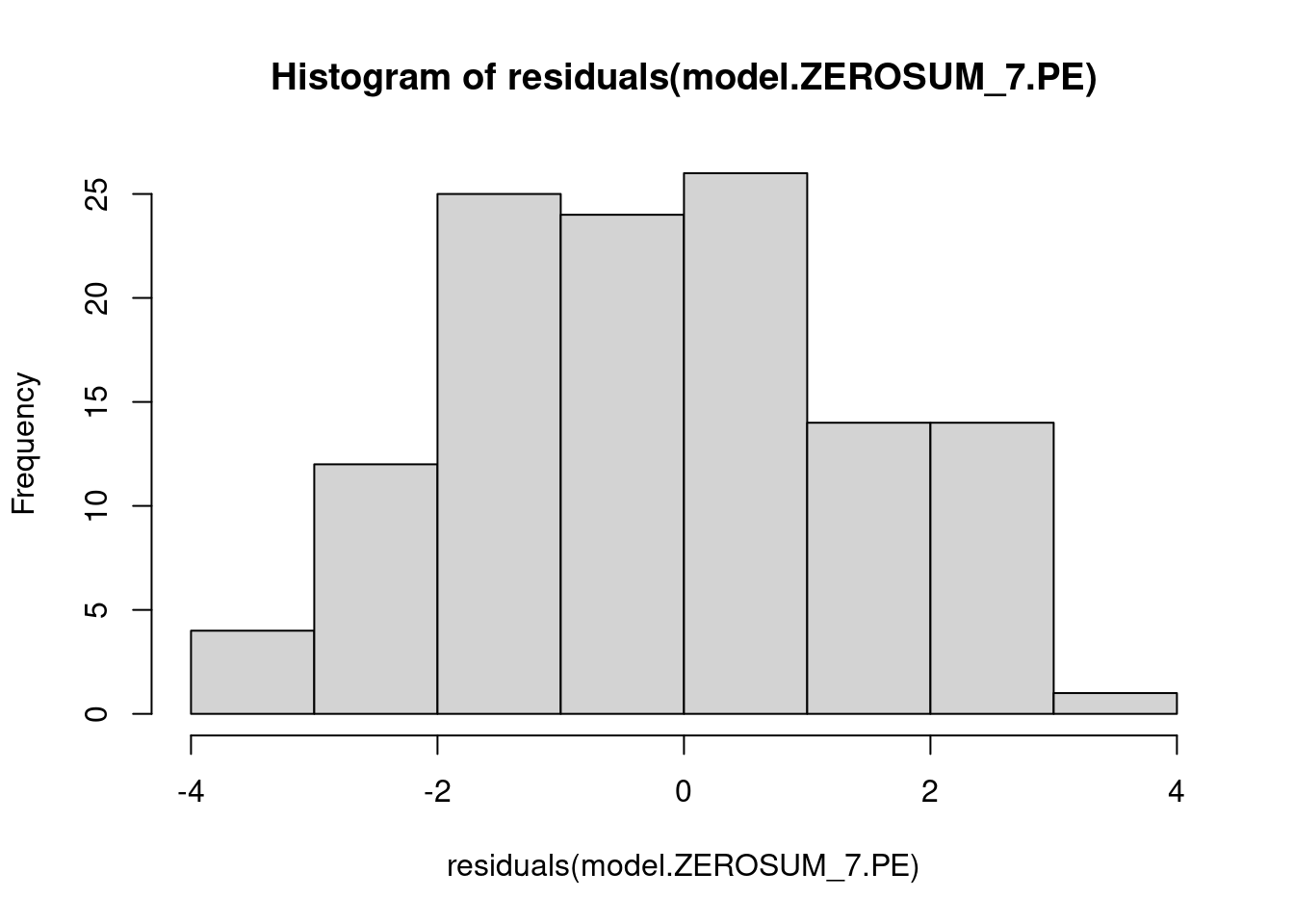
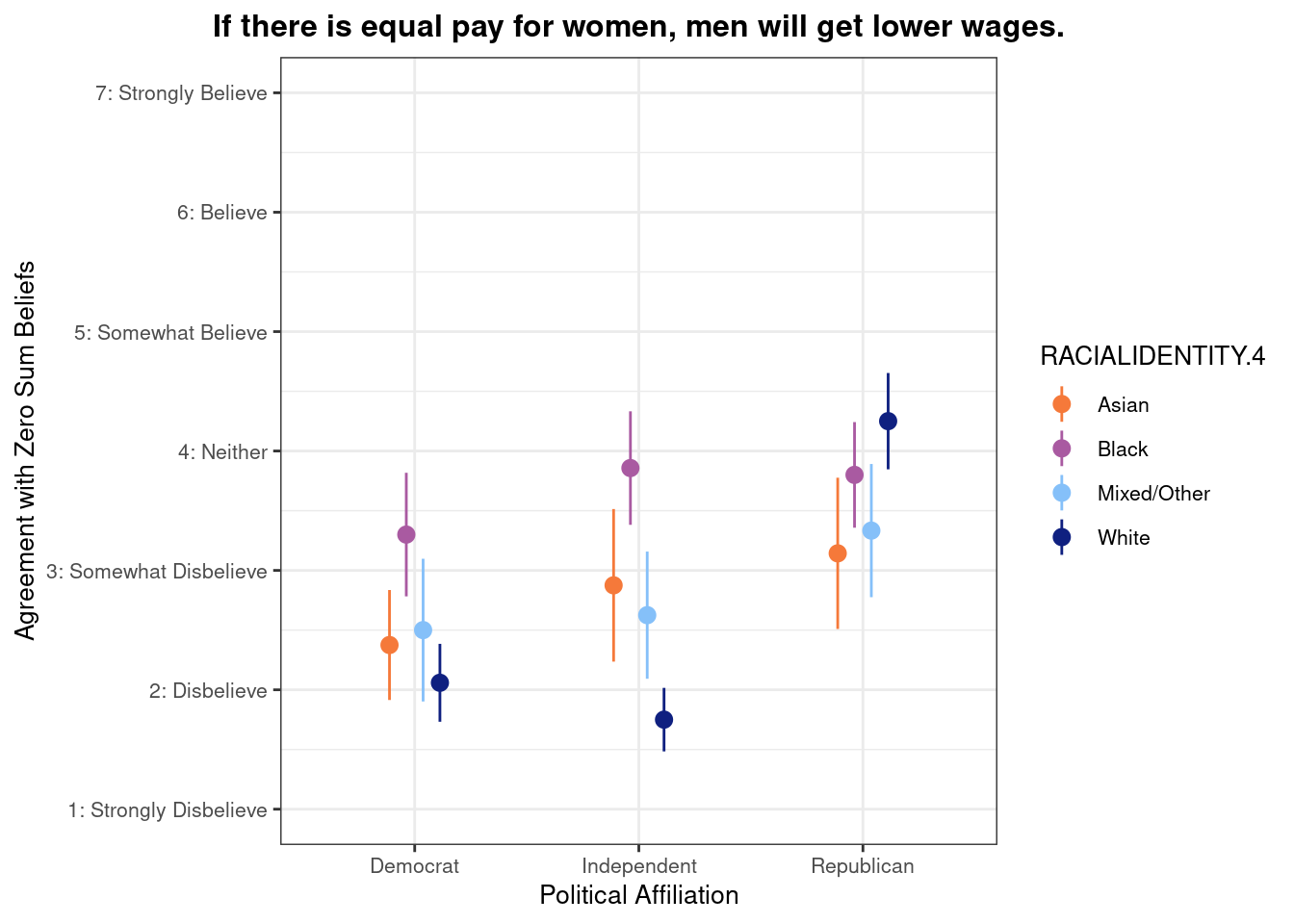
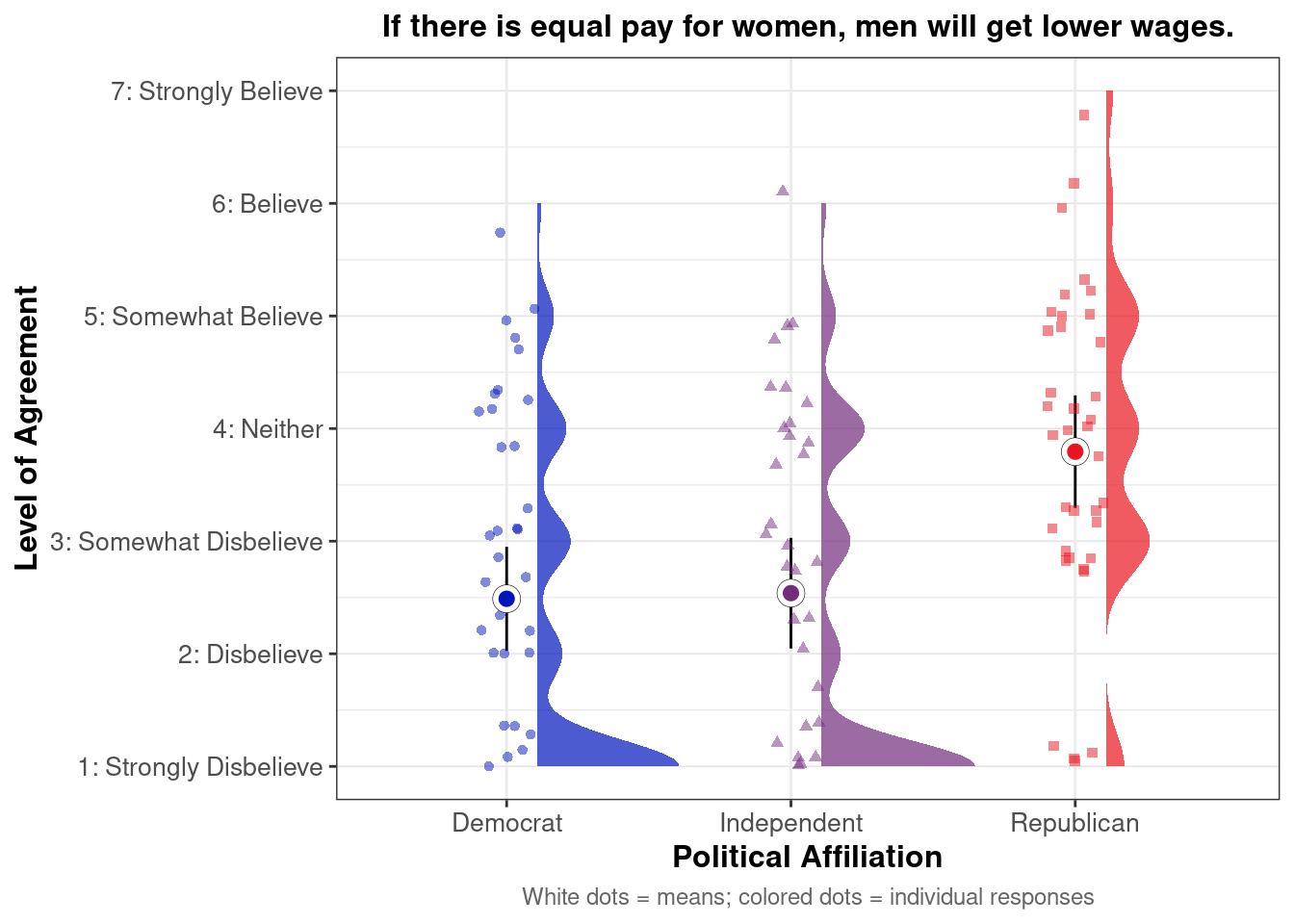
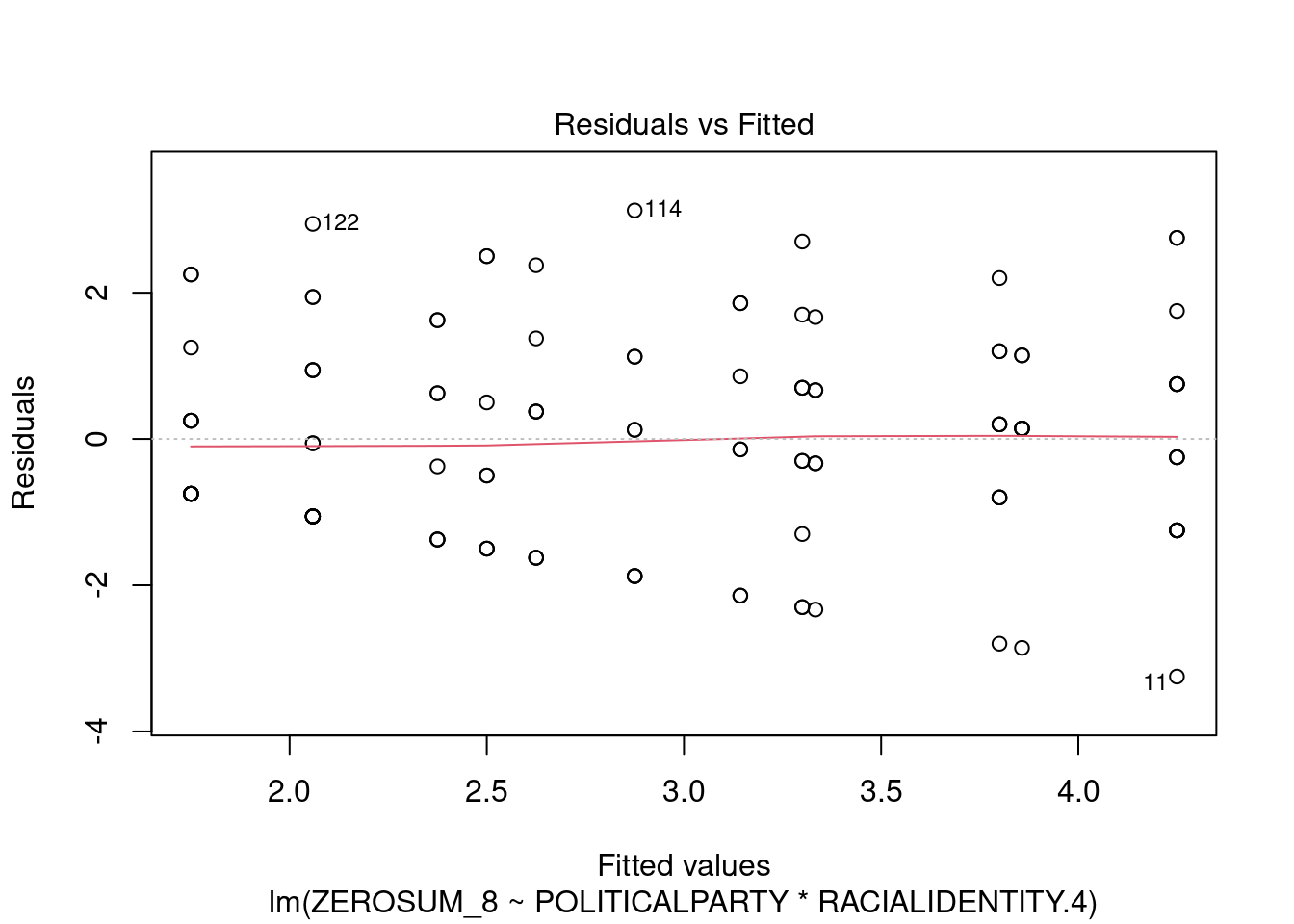
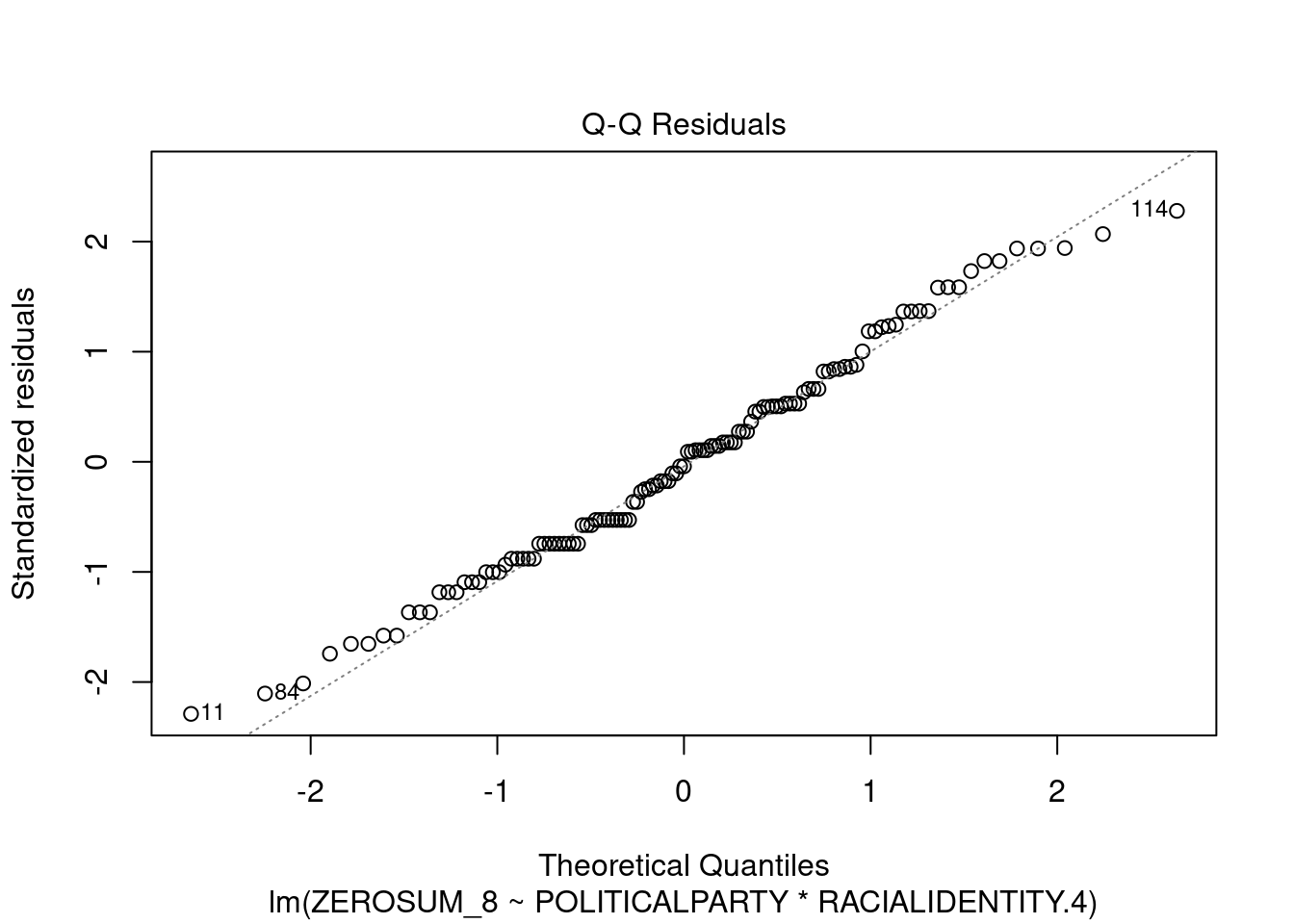
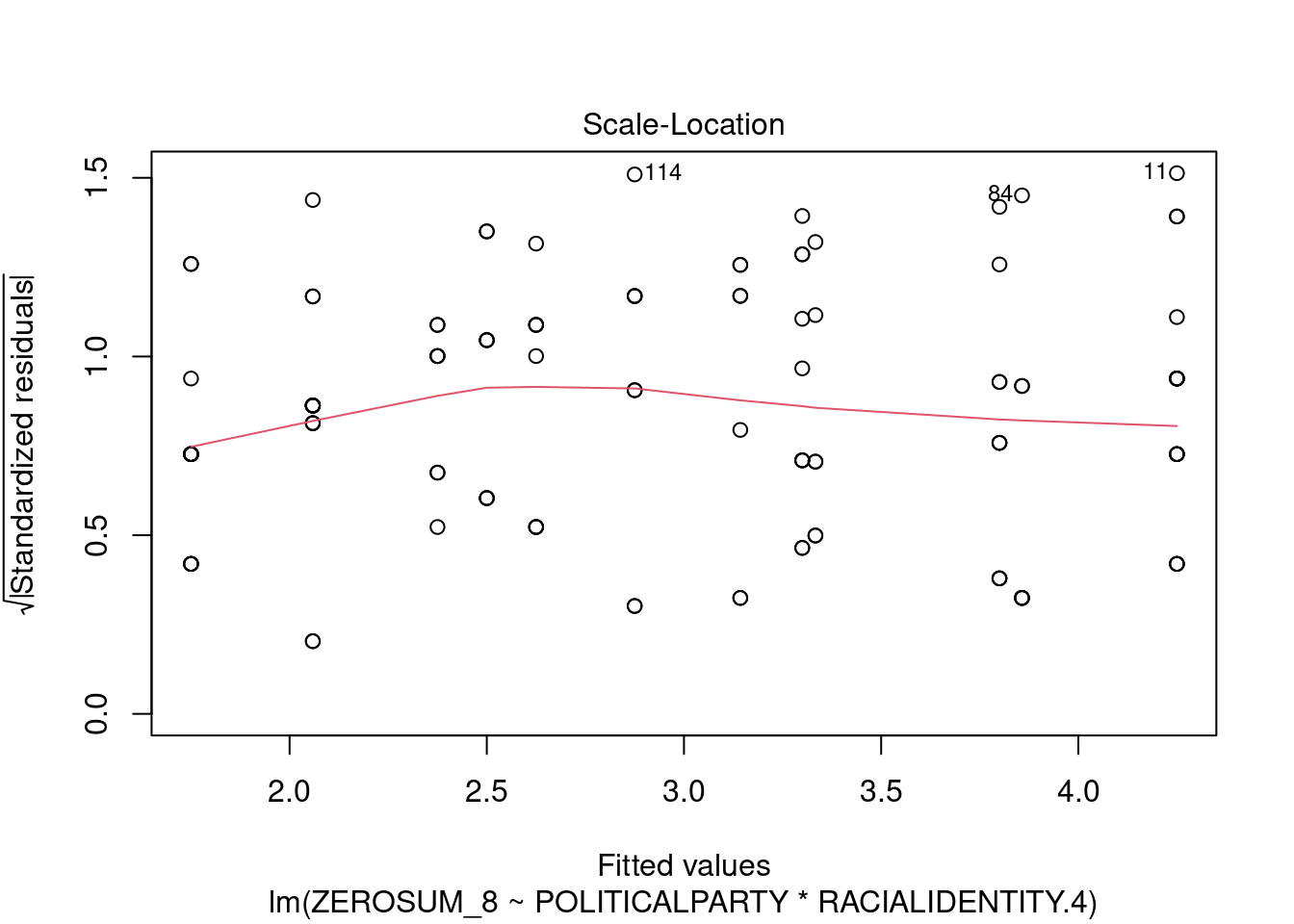
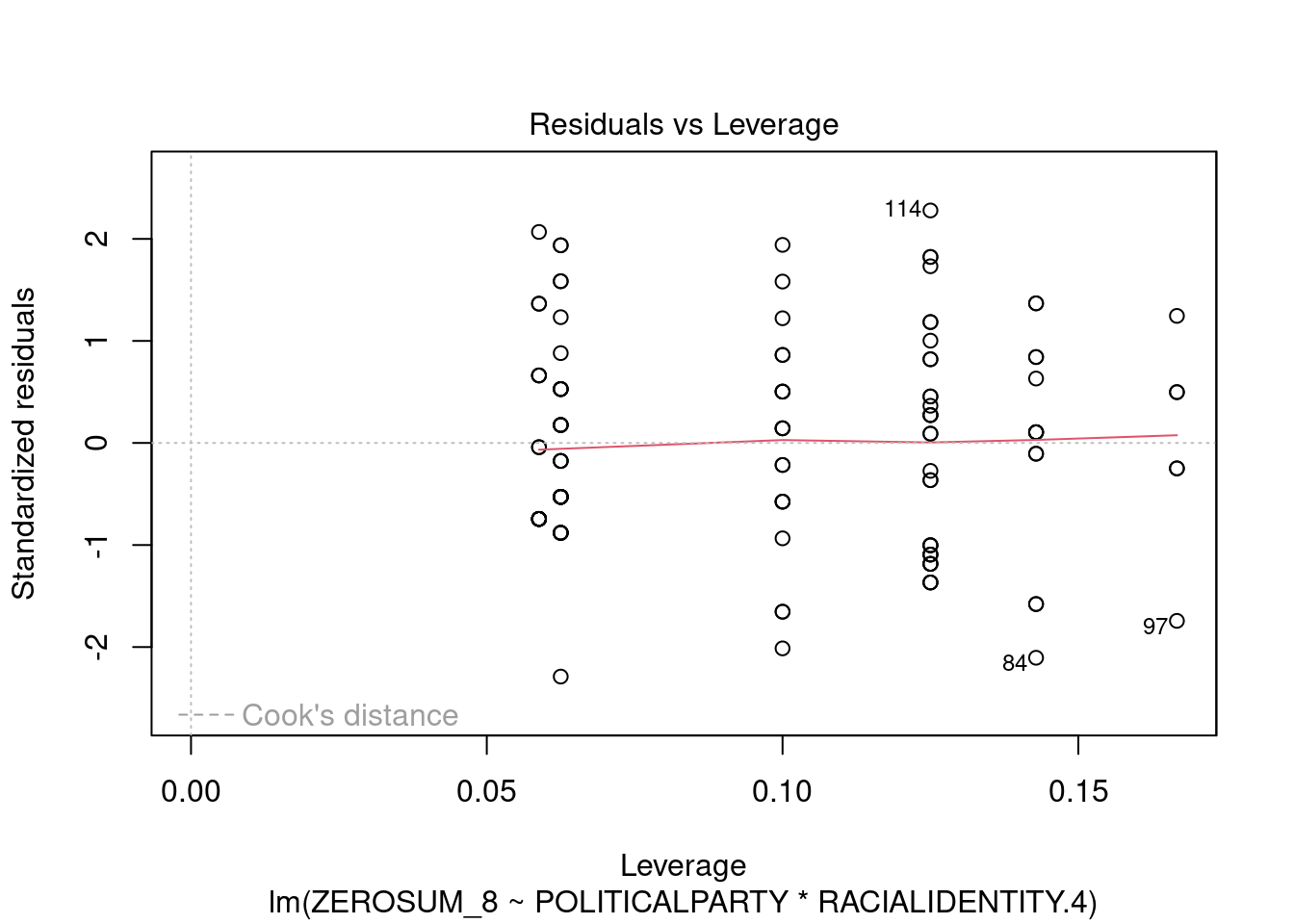
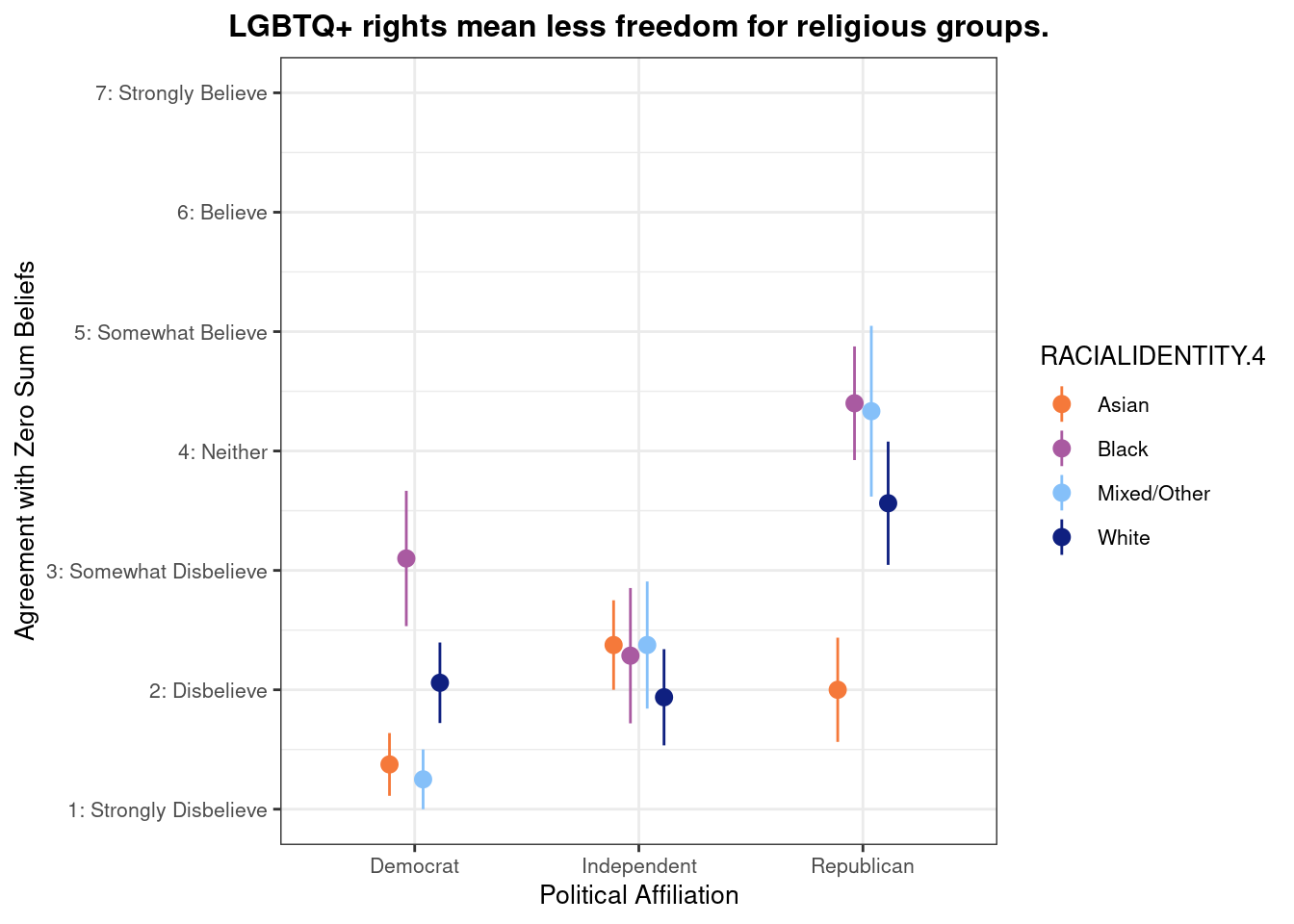
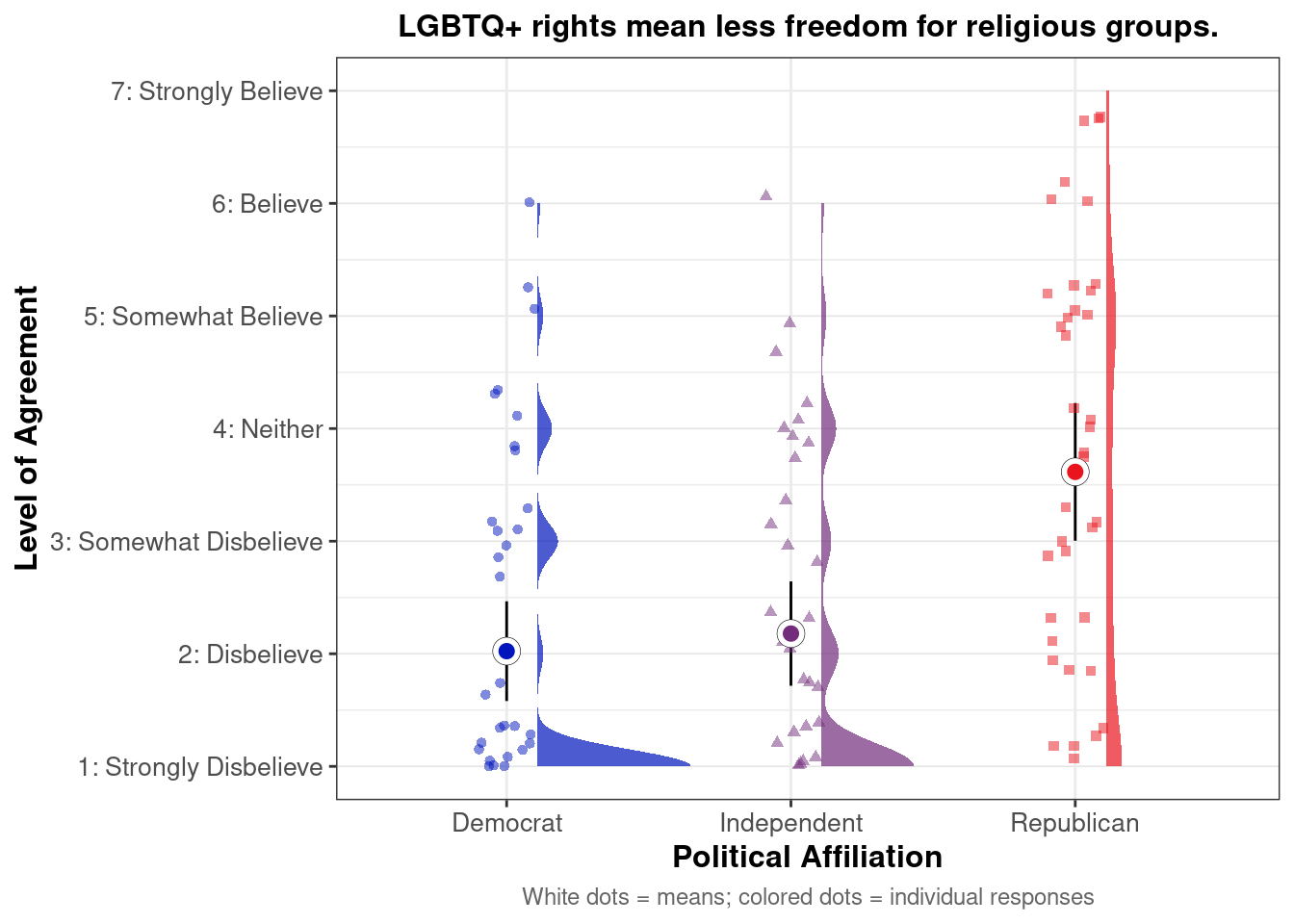
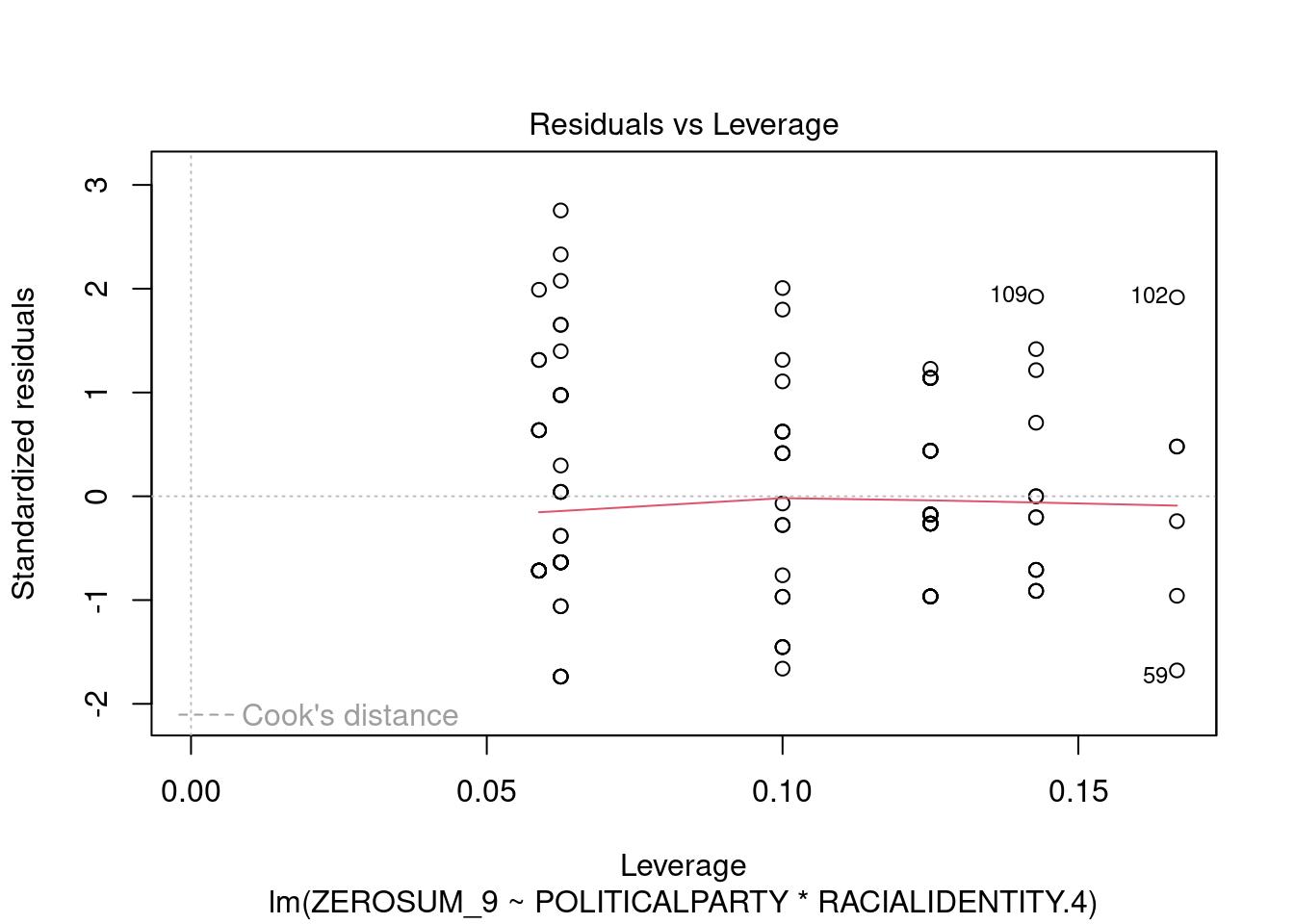
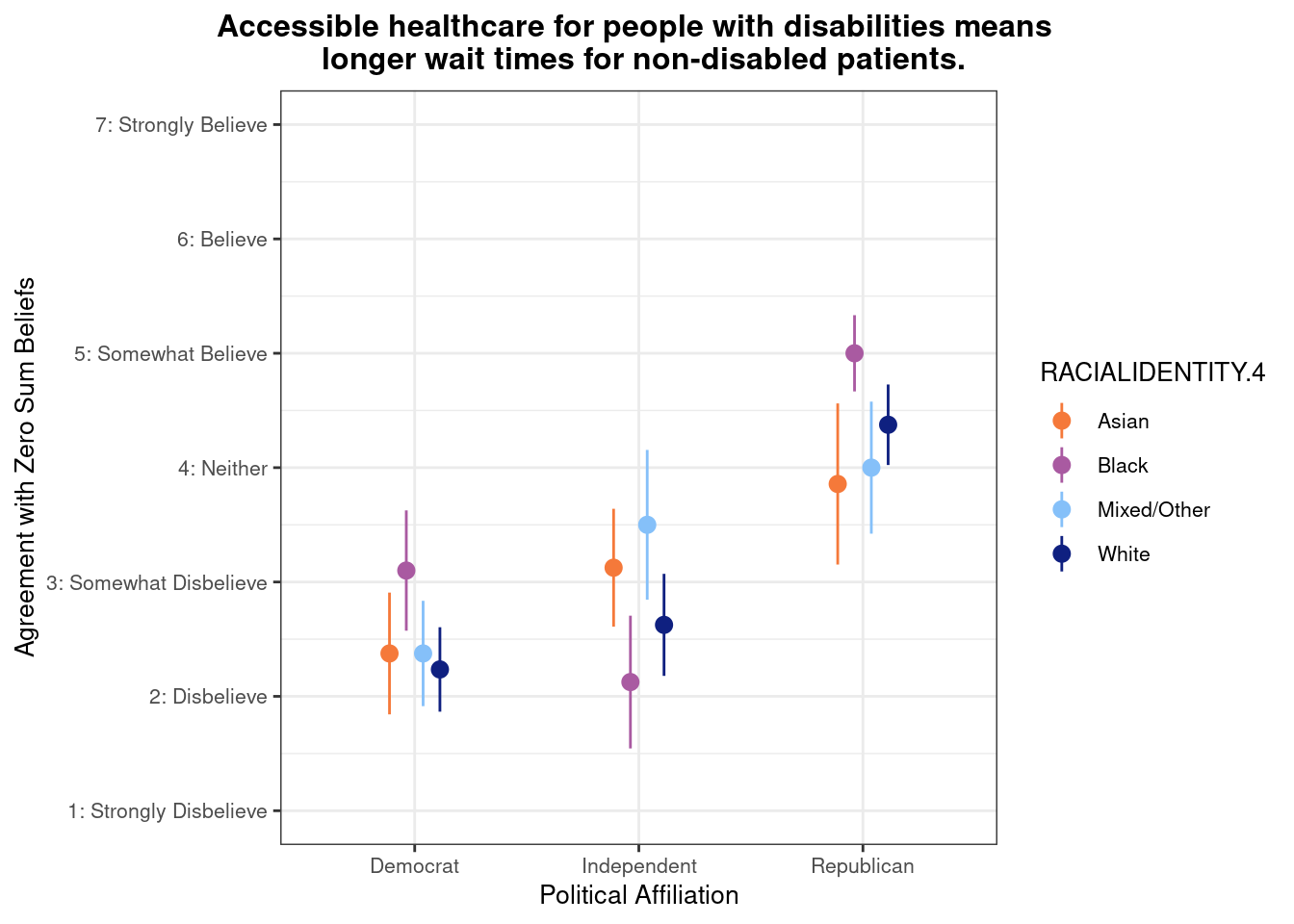
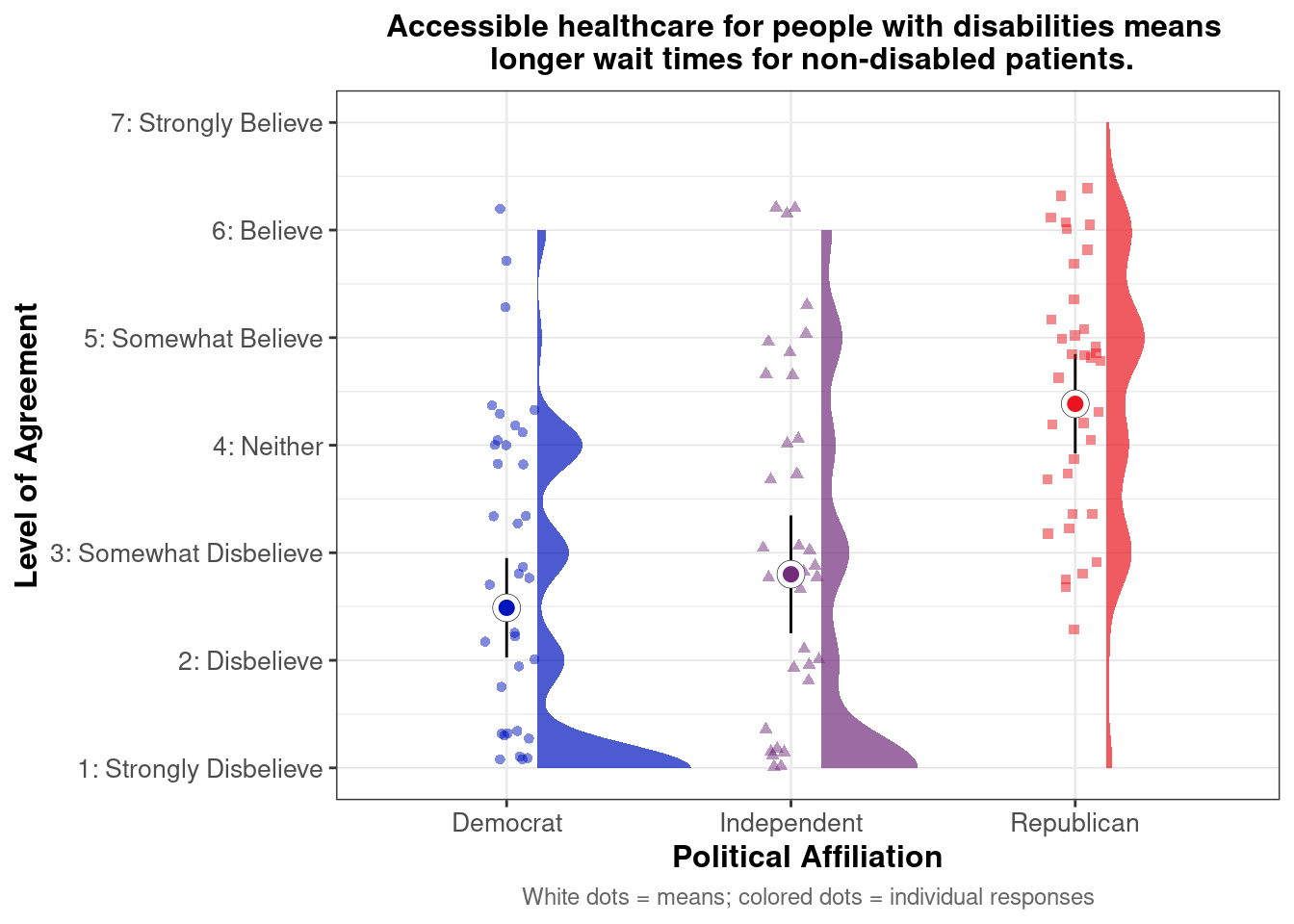
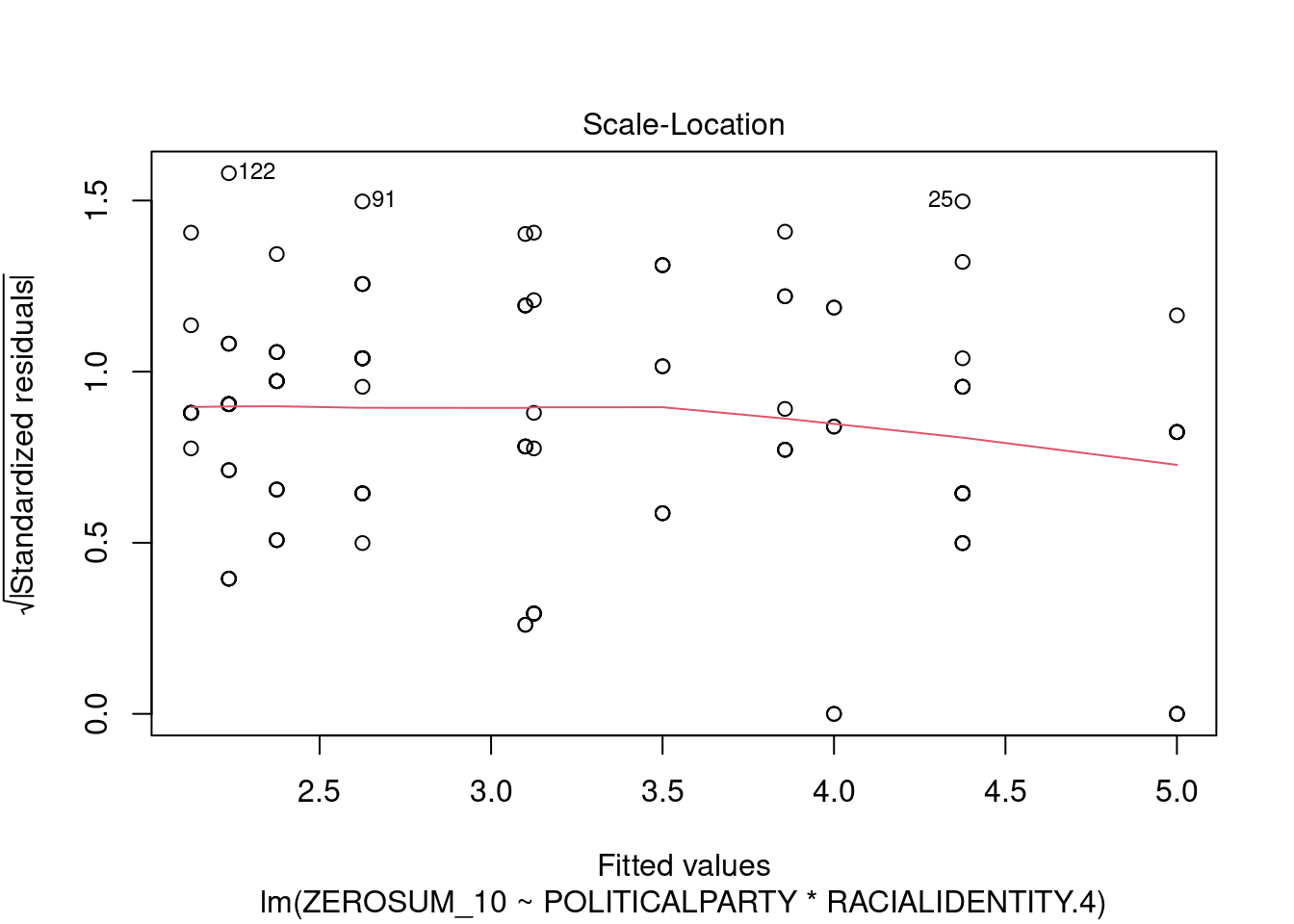
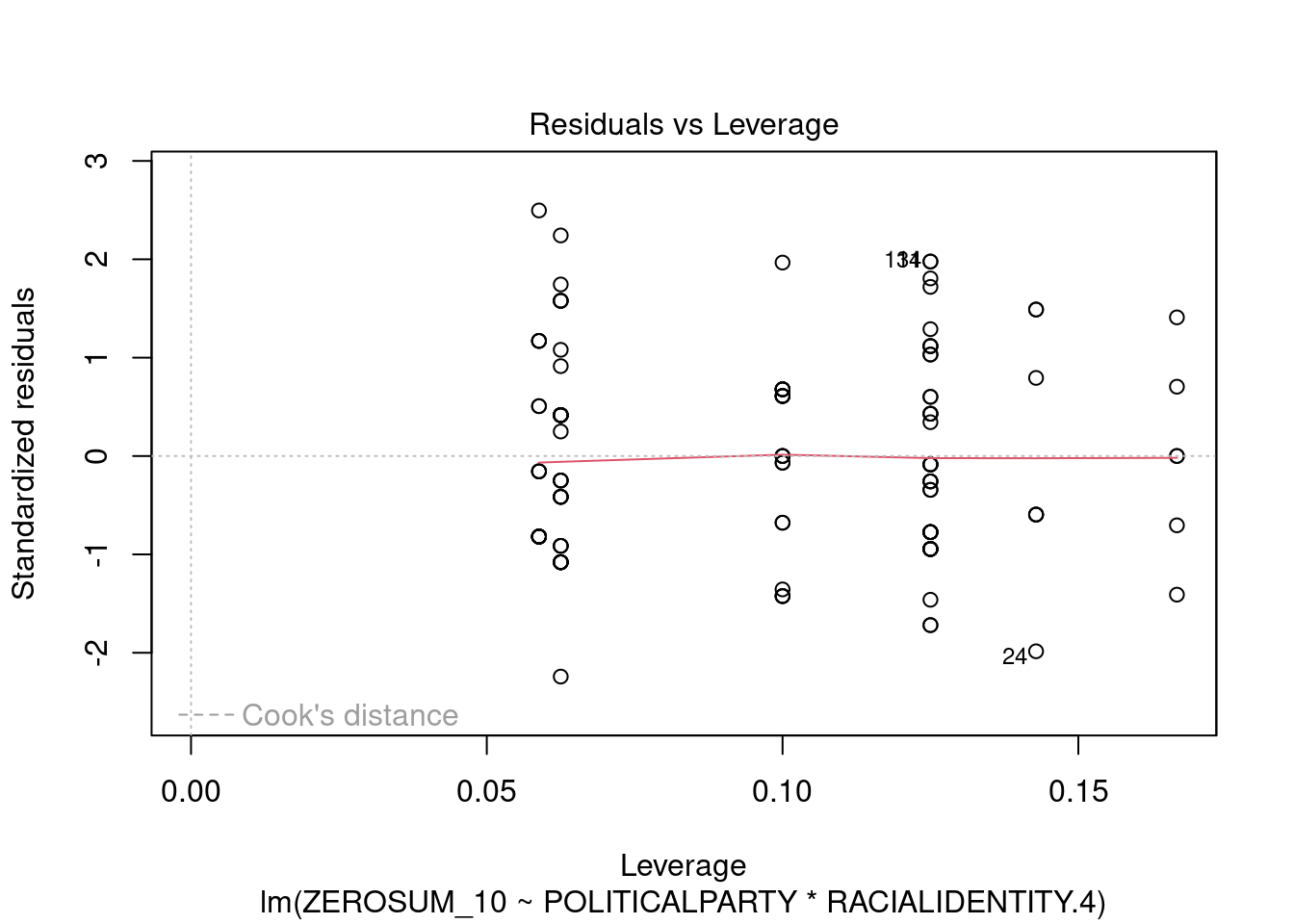
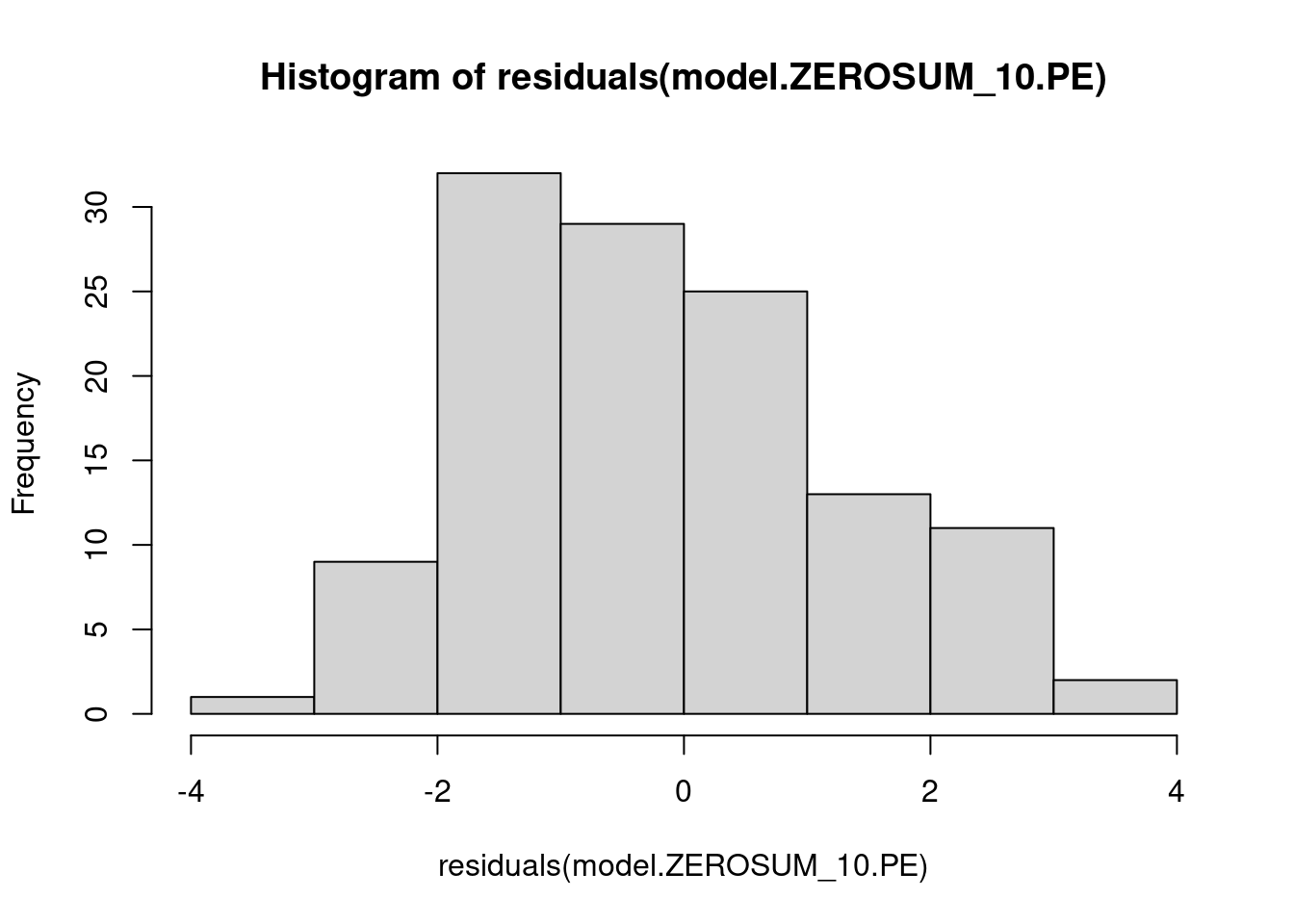
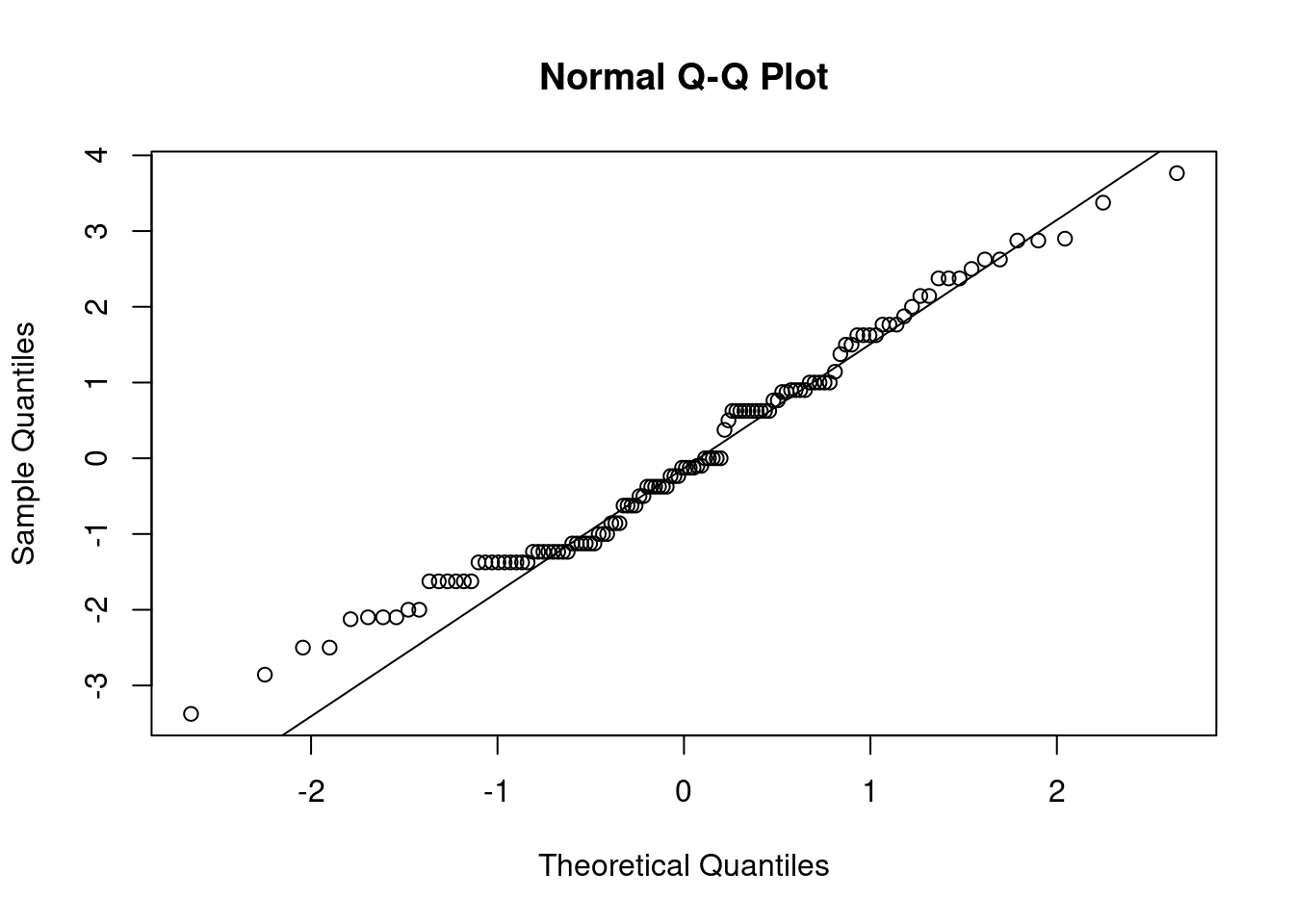
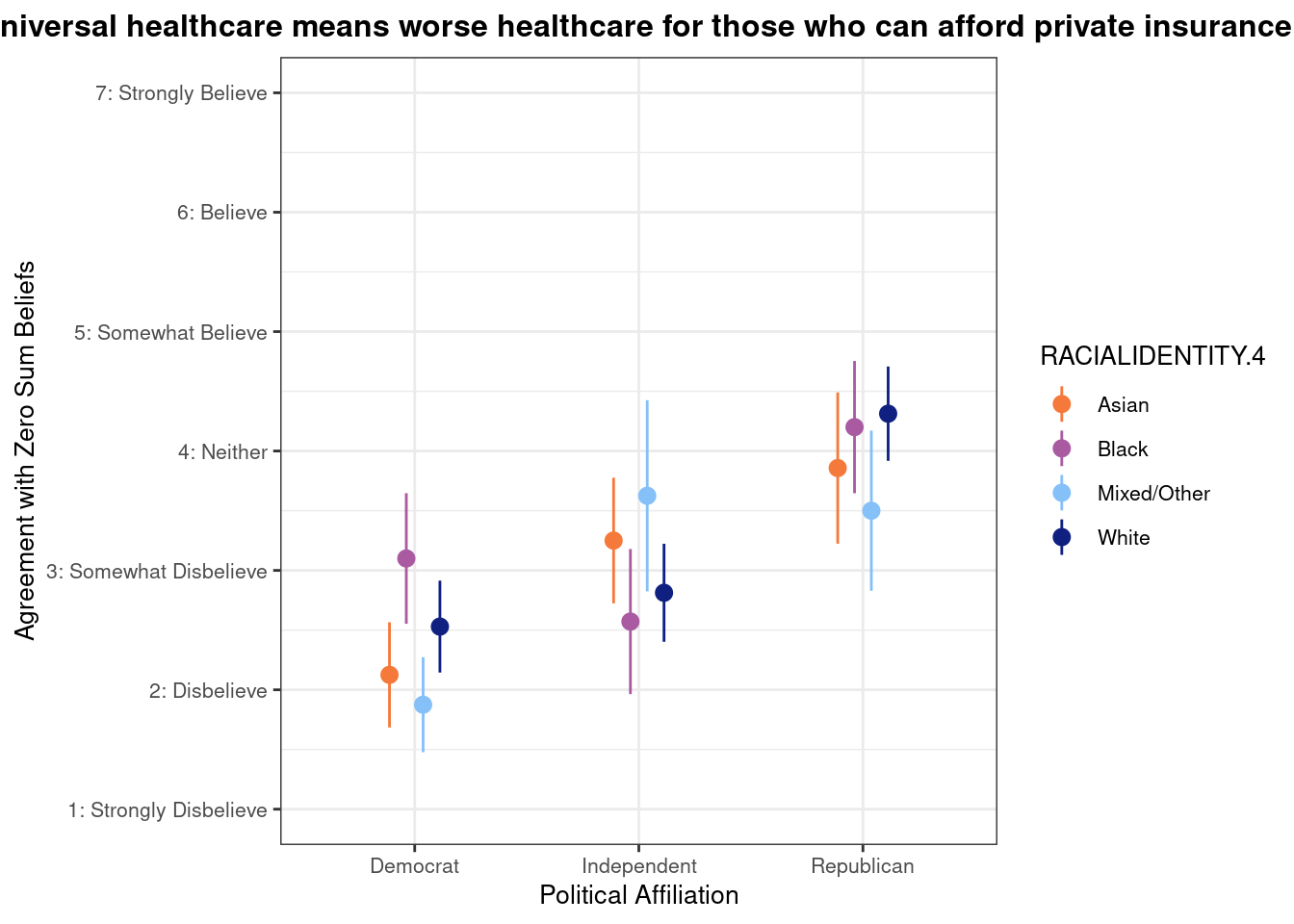
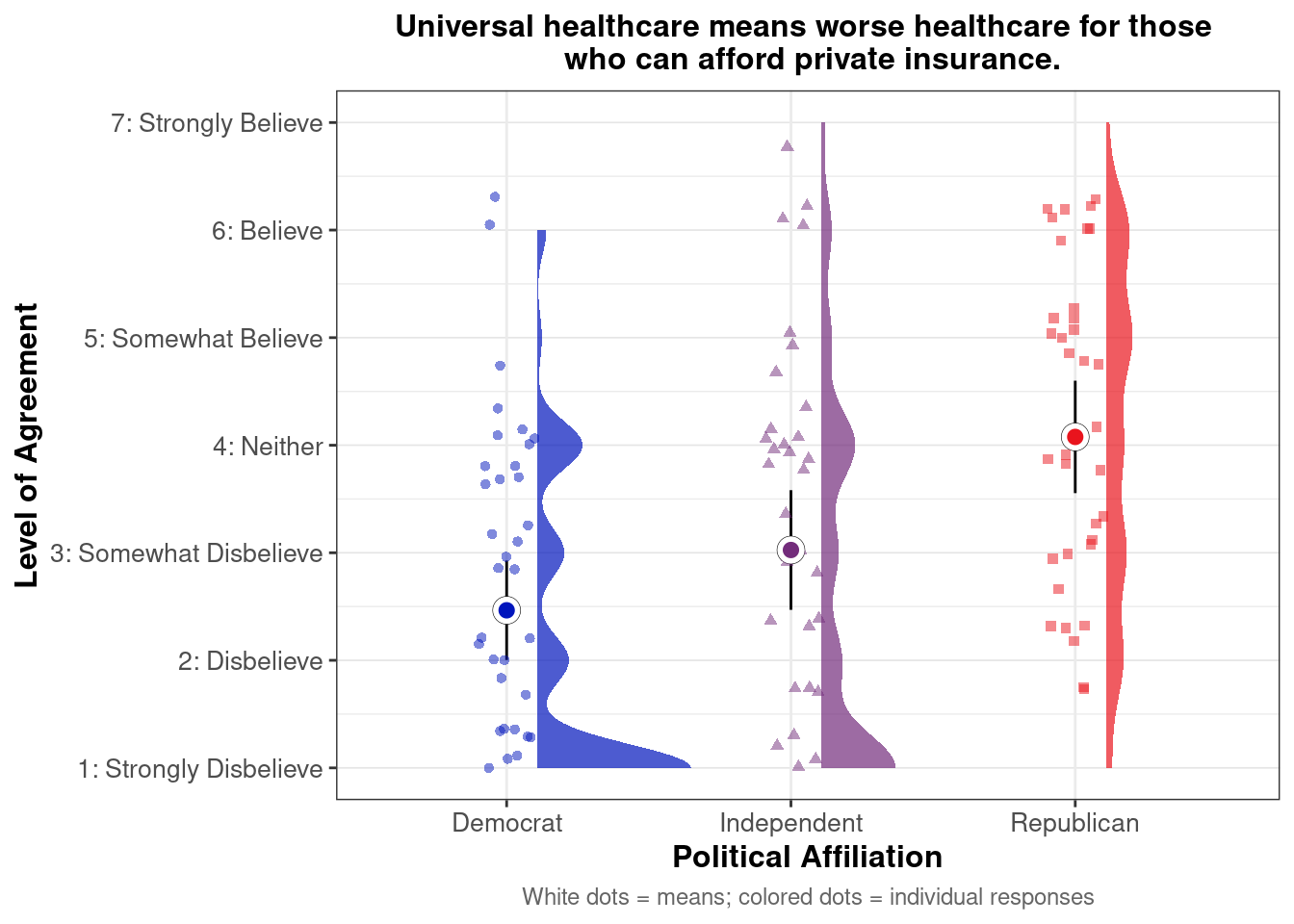
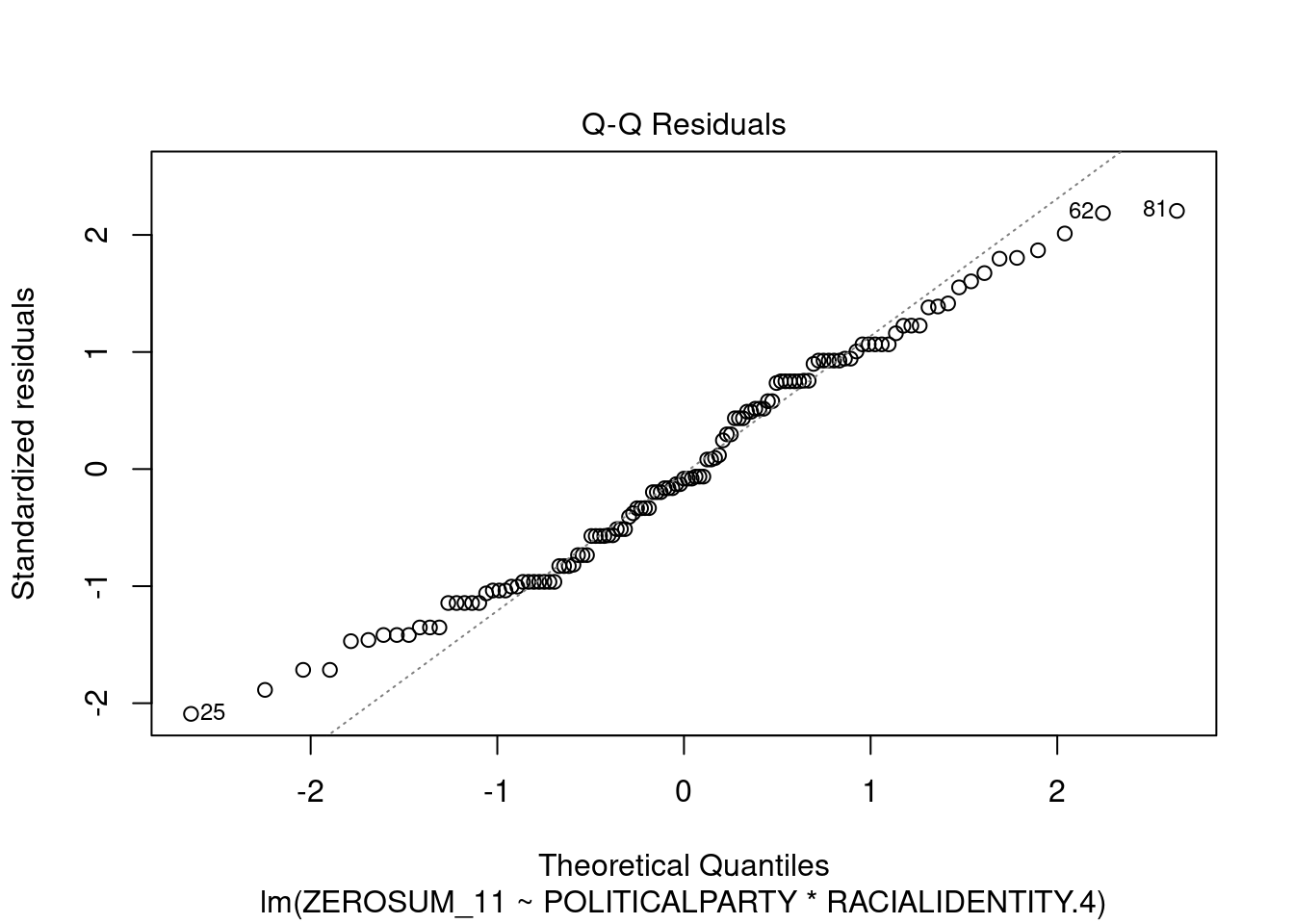
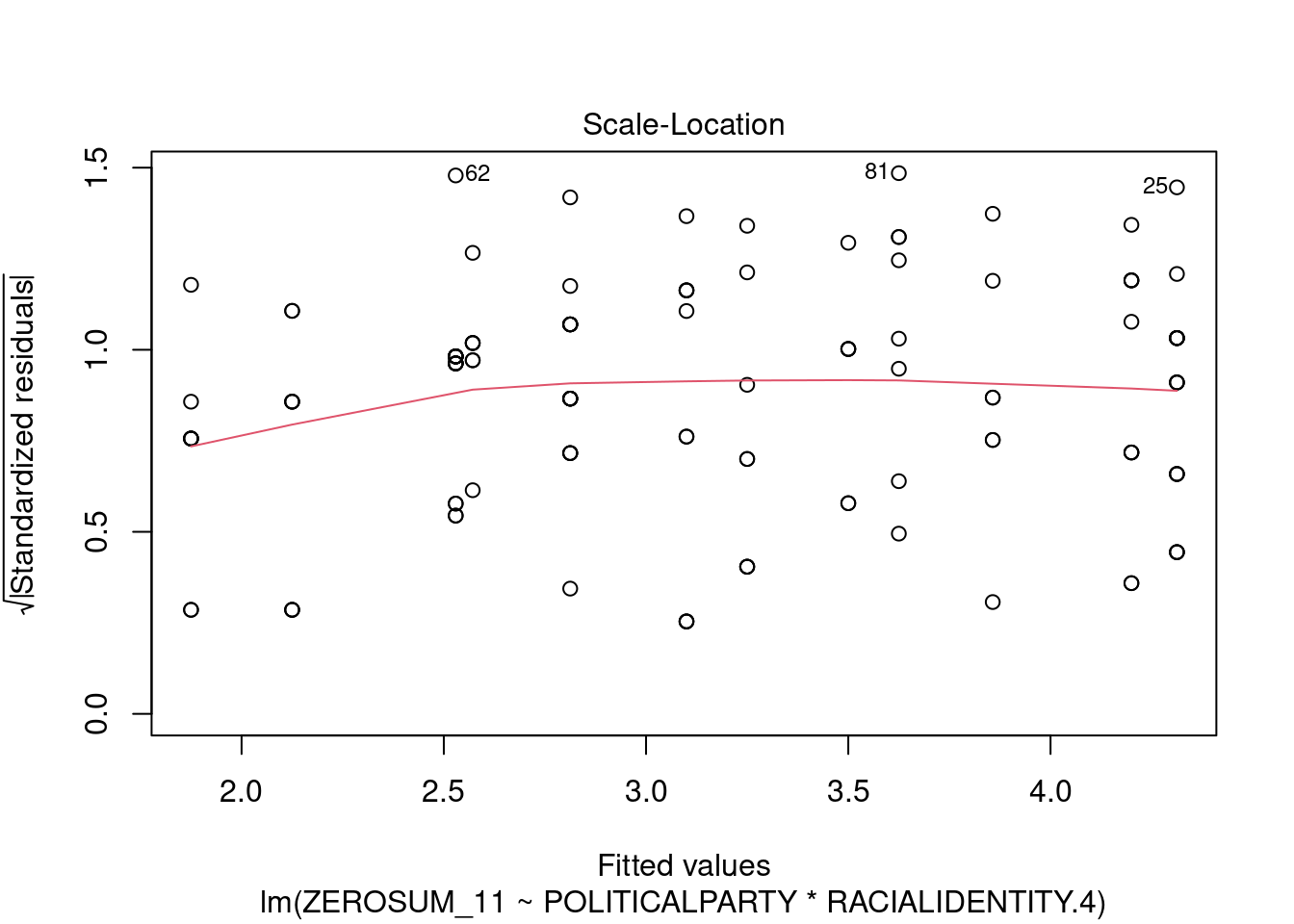
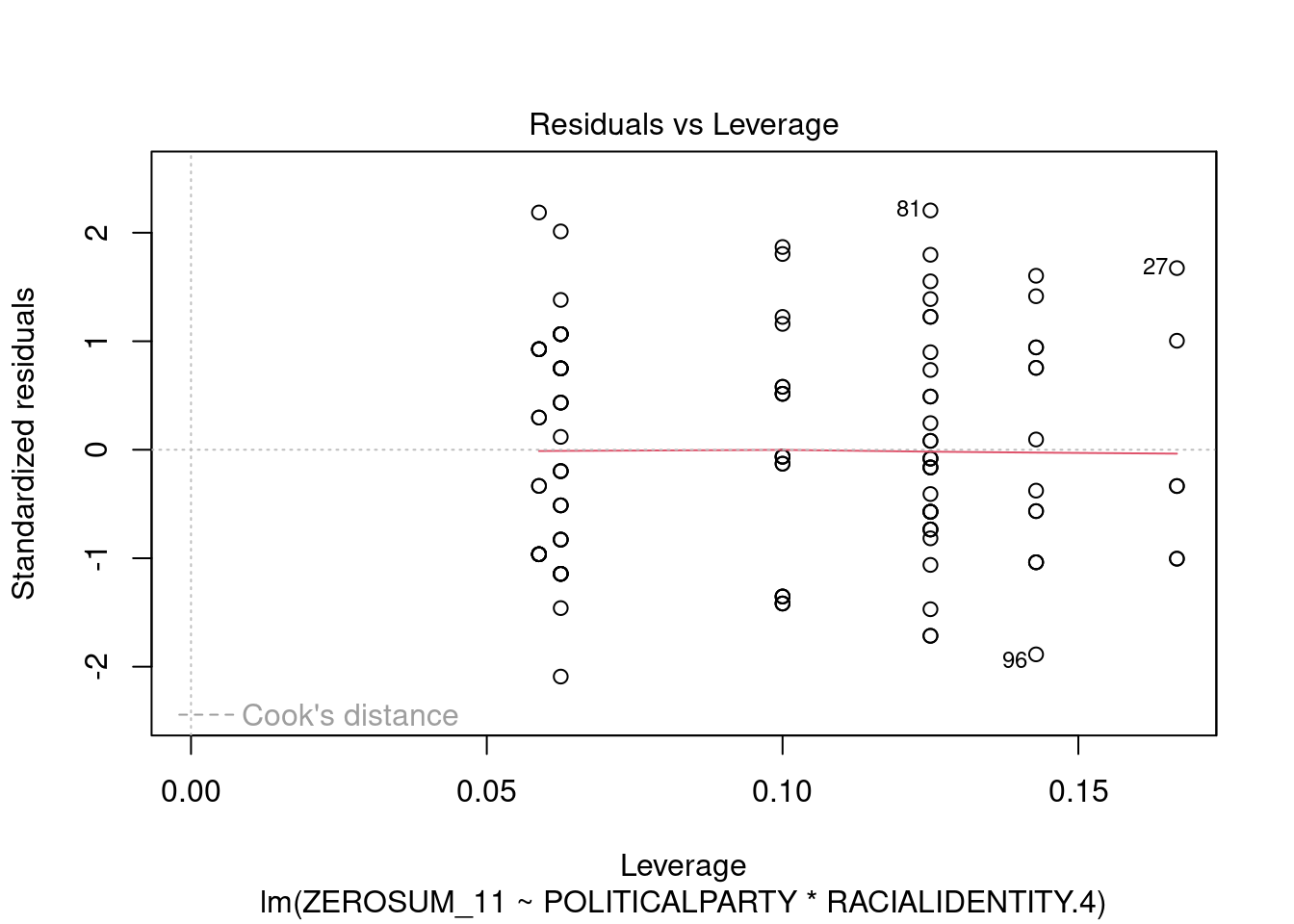
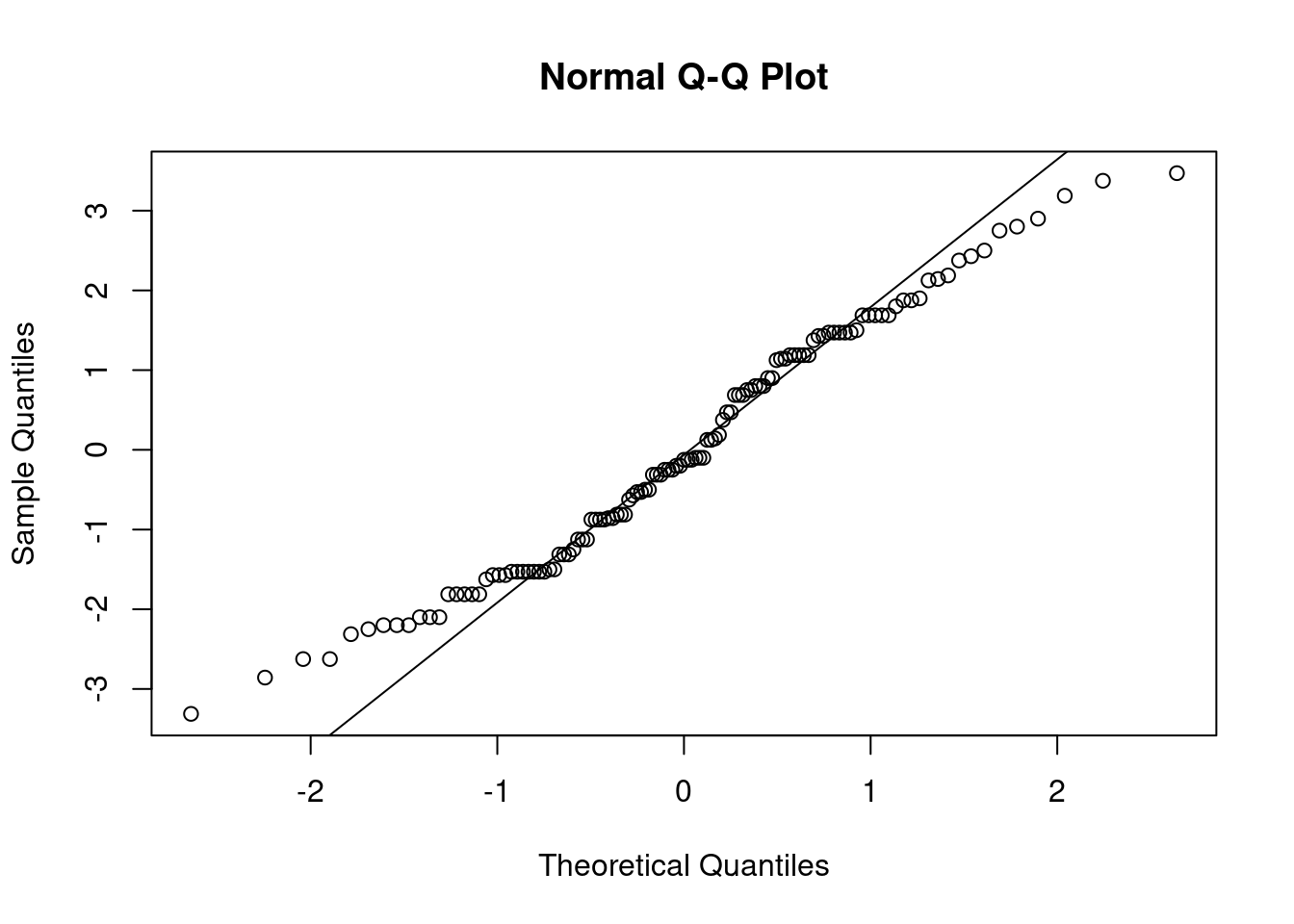
## This chunk creates a "raincloud plot" to visualize the distribution of ZEROSUM_1 scores by political party.
## Raincloud plots combine density shapes, raw data points, and summary stats (mean + CI).
plot.zerosum1_raincloud <- select_data %>%
filter(!is.na(ZEROSUM_1), !is.na(POLITICALPARTY)) %>%
ggplot(aes(x = POLITICALPARTY, y = ZEROSUM_1, fill = POLITICALPARTY, color = POLITICALPARTY)) +
## Half-eye density shows the distribution shape (like a smoothed histogram).
stat_halfeye(
adjust = 0.5,
width = 0.6,
.width = 0,
justification = -0.2,
point_colour = NA,
alpha = 0.7
) +
## Add 95% confidence intervals from earlier calculations
geom_pointrange(
data = group_stats_1_avg,
aes(
x = POLITICALPARTY,
y = mean_ZEROSUM_1,
ymin = ci_lower,
ymax = ci_upper
),
color = "black",
size = 0.9,
shape = 21,
fill = "white",
stroke = 1.2,
inherit.aes = FALSE
) +
## Add jittered raw data points (each dot = individual response)
geom_point(
aes(shape = POLITICALPARTY),
size = 1.5,
alpha = 0.5,
position = position_jitter(
seed = 1, width = 0.1 # keeps jitter reproducible
)
) +
## Overlay group means as white dots
stat_summary(
fun = mean,
geom = "point",
size = 3,
color = "white",
stroke = 1.5,
shape = 21
) +
## Color palette and theming
scale_fill_manual(values = party_colors) +
scale_color_manual(values = party_colors) +
theme_bw() +
labs(
title = "Life is so devised that when somebody gains, others have to lose.",
x = "Political Affiliation",
y = "Level of Agreement",
caption = "White dots = means; colored dots = individual responses"
) +
theme(
plot.title = element_text(size = 12, face = "bold", hjust = 0.5),
plot.caption = element_text(size = 9, color = "gray40", hjust = 0.5),
axis.title = element_text(size = 12, face = "bold"),
axis.text = element_text(size = 10),
legend.position = "none",
panel.grid.major.y = element_line(color = "gray90", linewidth = 0.3)
) +
## Match axis scale to Likert-style labels for interpretation
scale_y_continuous(
breaks = 1:7,
labels = c("1: Strongly Disbelieve",
"2: Disbelieve",
"3: Somewhat Disbelieve",
"4: Neither",
"5: Somewhat Believe",
"6: Believe",
"7: Strongly Believe"),
limits = c(1, 7)
)
## Show the final plot
plot.zerosum1_raincloud