Abstract
Background: Zero-sum beliefs—the perception that one group’s gains necessarily result in another group’s losses—are important predictors of political attitudes. However, the referents for zero-sum beliefs as economic or social identity remain underexplored in relation to political ideology, party affiliation, and voting behavior in contemporary elections.
Method: We conducted a comprehensive analysis examining three dimensions of zero-sum beliefs (general, economic, and social identity). Using Kruskal-Wallis tests on eleven zero-sum beliefs, we investigated how political party affiliation and racial/ethnic identity influenced endorsement of zero-sum beliefs across multiple domains. Subsequently, we examined whether these zero-sum belief patterns predicted self-reported voting for Donald Trump versus Kamala Harris in the 2024 presidential election.
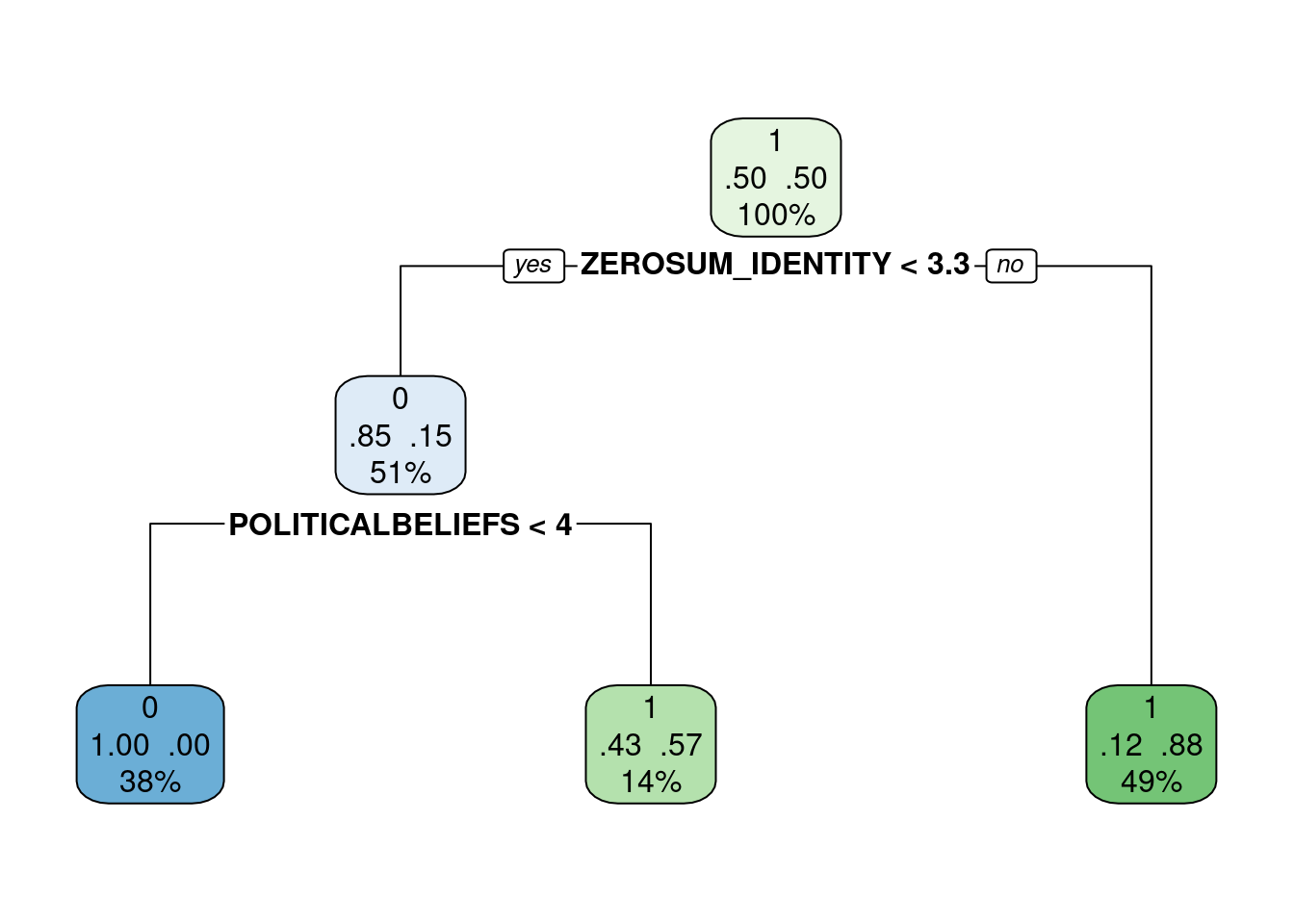
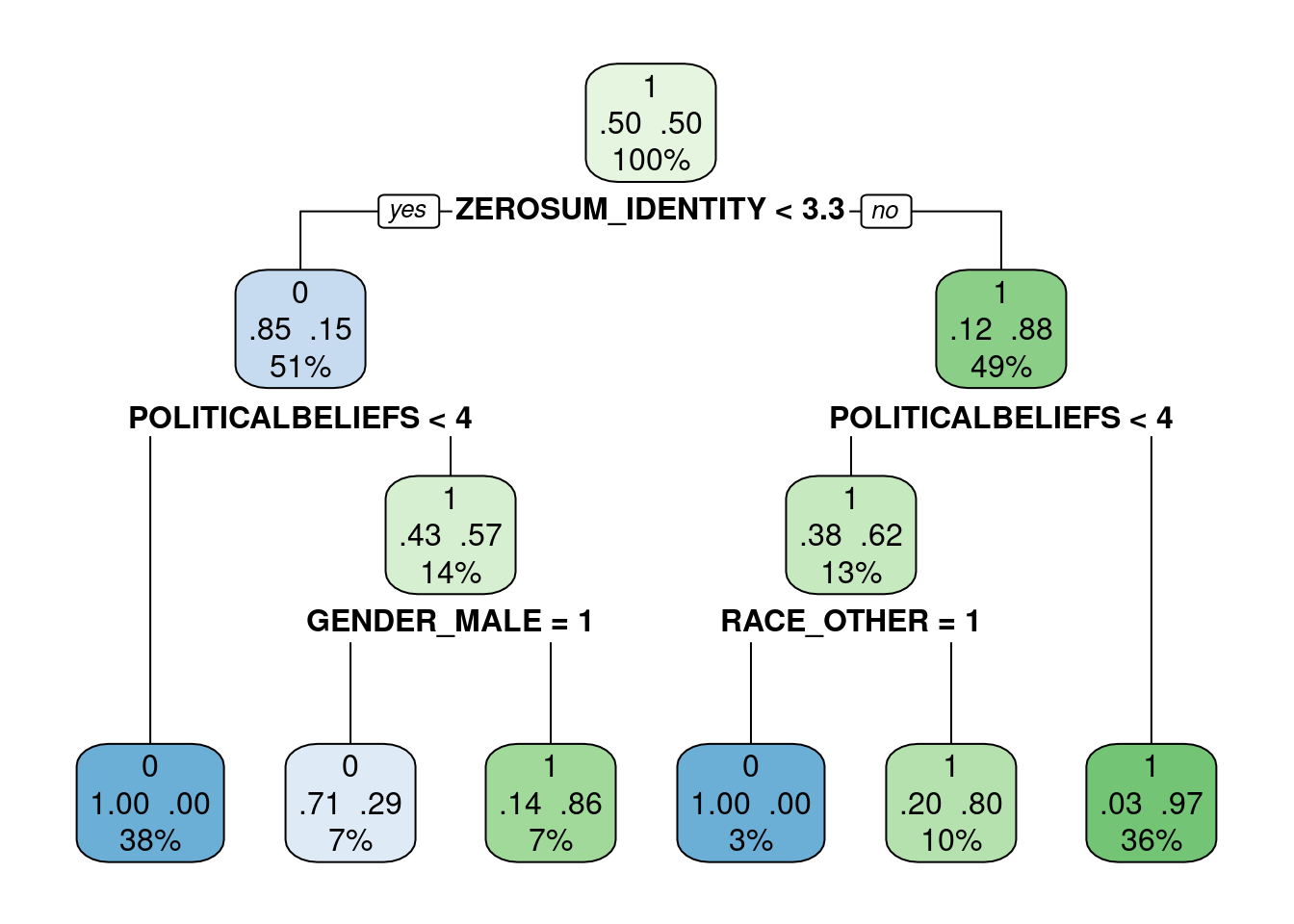
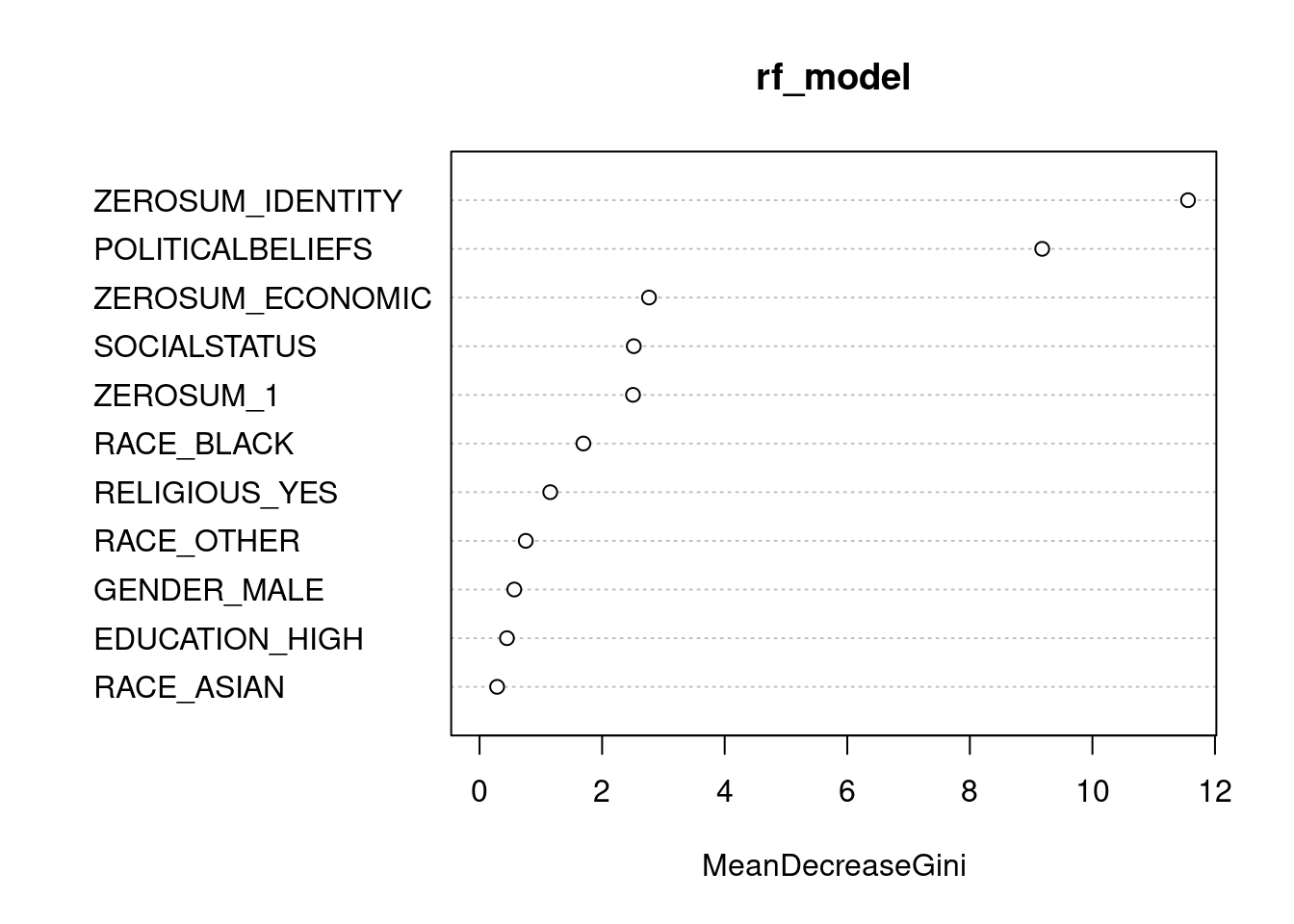
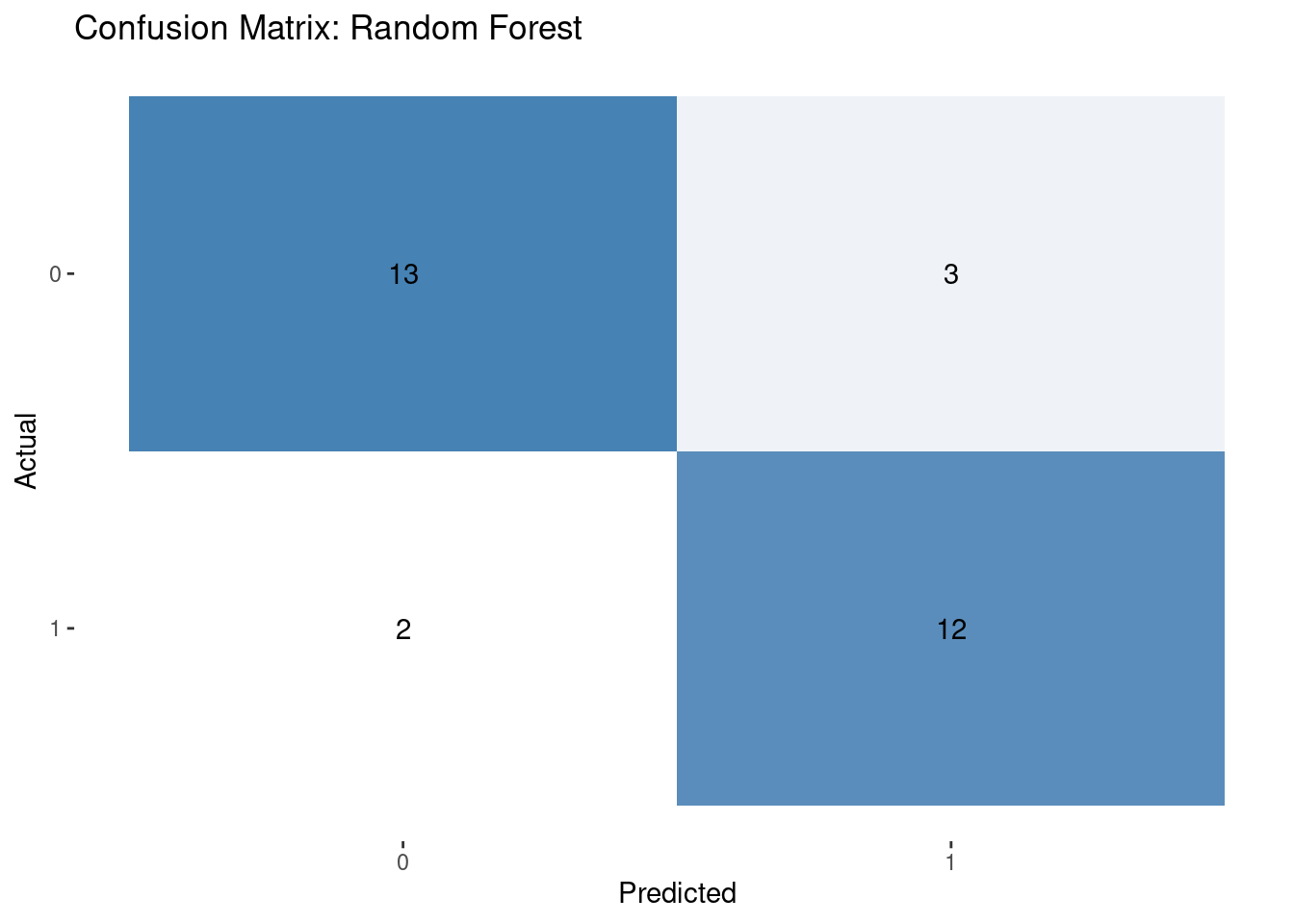
Results: Political party affiliation was a significant predictor for all eight zero-sum social identity beliefs, but none of the economic or general beliefs. Republican voters and certain racial/ethnic groups demonstrated higher endorsement of zero-sum social identity beliefs. A logistic regression shows that after controlling for political ideology, a composite of zero-sum social identity beliefs explains voting behavior in the 2024 presidential election, with stronger zero-sum social identity thinking associated with Trump support and lower zero-sum social identity beliefs predicting Harris support. Other sociodemographic factors and zero-sum economic thinking were not significant predictors.
Discussion: Zero-sum social identity beliefs may represent a competitive core belief underlying contemporary political party affiliation and candidate preference. These findings affirm prior work that zero-sum thinking about economics differ from social identities, with similar levels of agreement on zero-sum economic beliefs across political parties but significantly different levels of agreement on zero-sum social identity beliefs by party affiliation. To the best of our knowledge, this study is the first to show that zero-sum thinking about social identities predicts voter preference in the 2024 election. Ultimately, future work needs to examine how to reduce zero-sum social identity thinking.